第 0 课:安装与测试
Python 环境配置教程请移步这里 Python 安装
(一) 安装 Cuda
Cuda 是进行人工智能工作的必不可少的工具,我们需要依次安装 Cuda 和 **cudnn **
如果没有 Sudo 权限也没关系,请直接跳过这一小节,跳转到 使用 conda 安装 Pytorch
步骤一:安装 Cuda
CUDA 是 NVIDIA 推出的并行计算平台和编程模型,允许开发者利用 GPU 进行通用计算。它的核心特点包括:
- 并行计算:通过 GPU 上的大量核心同时执行任务,提高计算效率。
- C 语言扩展:CUDA 提供了一套 C/C++ 的 API,使开发者能够编写 GPU 代码(CUDA 核函数)。
- 深度学习支持:CUDA 是许多深度学习框架(如 TensorFlow、PyTorch)的计算基础。
简而言之,我们之后学习的深度学习框架,都是通过 Cuda 间接控制 GPU 的。
打开一个终端,依次执行下面的指令
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pin
sudo mv cuda-wsl-ubuntu.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.6.2/local_installers/cuda-repo-wsl-ubuntu-12-6-local_12.6.2-1_amd64.deb
sudo dpkg -i cuda-repo-wsl-ubuntu-12-6-local_12.6.2-1_amd64.deb
sudo cp /var/cuda-repo-wsl-ubuntu-12-6-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda-toolkit-12-6
然后配置环境变量
sudo vim ~/.bashrc
在文件末加上下面这些内容
export CUDA_HOME=/usr/local/cuda-12.6
export PATH=/usr/local/cuda-12.6/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.6/lib64:$LD_LIBRARY_PAT
注意这个12.6 是会随着版本号更新的,使用的使用注意修改
刷新命令行
source ~/.bashrc
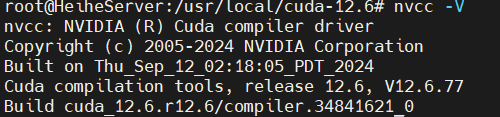
显示 CUDA 编译器的版本信息
nvcc -V
步骤二:安装 cudnn
cuDNN 是 NVIDIA 提供的 GPU 加速库,专门用于深度学习计算。它基于 CUDA,用于加速常见的神经网络运算,如:
- 卷积(Convolution)
- 池化(Pooling)
- 归一化(Normalization)
- 激活函数(Activation Functions)
cuDNN 主要用于加速深度学习框架(如 TensorFlow、PyTorch、MXNet 等),使其能够更高效地在 NVIDIA GPU 上运行。
CUDA 与 cuDNN 的关系
- CUDA 是底层 GPU 计算平台,提供通用并行计算能力。
- cuDNN 是 CUDA 之上的深度学习专用优化库,简化和加速神经网络计算。
在深度学习任务中,一般需要 同时安装 CUDA 和 cuDNN 才能正常利用 GPU 进行训练。
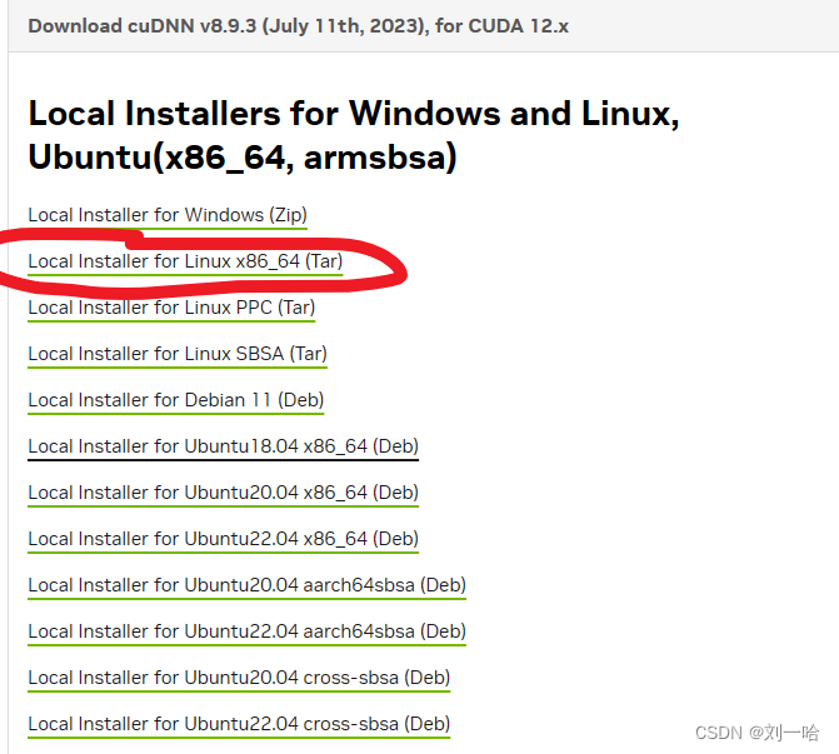
解压文件,并将其放入cuda对应的文件中
tar -xvf cudnn-linux-x86_64-8.9.7.29_cuda12-archive.tar.xz
sudo cp cudnn-*-archive/include/cudnn*.h /usr/local/cuda-12.6/include
sudo cp -P cudnn-*-archive/lib/libcudnn* /usr/local/cuda-12.6/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda-12.6/lib64/libcudnn*
检查版本
cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2

由于我们已经将 cuDNN 的相关文件从 cudnn-linux-x86_64-8.9.7.29_cuda12-archive 文件夹复制到了 /usr/local/cuda-12.6 的相应目录中,所以用户根目录下的可以删了
rm -rf ~/cudnn-linux-x86_64-8.9.7.29_cuda12-archive
(二)安装 Pytorch
方法一:conda (推荐)
�访问 https://pytorch.org/get-started/locally/ 查询最新安装命令。
当前你的 CUDA 版本是 12.9,推荐以下安装命令:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
💡 虽然系统 CUDA 是 12.9,PyTorch 仍用自己打包的 CUDA 12.1 版本,它不依赖系统 CUDA,所以可以直接安装 cu121 版本即可。
方法二:pyenv
创建虚拟环境
pyenv virtualenv 3.12.4 pytorch_env
激活虚拟环境
pyenv activate pytorch_env
列出所有环境
pyenv virtualenvs
建议使用 pip 来安装 pytorch
pip install torch torchvision torchaudio
在激活虚拟环境后,建议使用 pip 安装依赖包,安装的包都将��仅在当前虚拟环境中可用
不要使用 conda 安装依赖包,因为 conda 安装好的包可能不是在 pyenv 的路径下
补充一下 使用conda 安装的方式 (不建议使用)
直接前往 Pytorch 官网:PyTorch

直接使用官方给出的命令
conda install pytorch torchvision torchaudio pytorch-cuda=12.4 -c pytorch -c nvidia
退出虚拟环境
pyenv deactivate
删除指定的虚拟环境
pyenv virtualenv-delete pytorch_env
使用下面这段 Python 代码测试一下 安装是否成功
import torch
print("PyTorch Version:", torch.__version__)
print("CUDA Available:", torch.cuda.is_available())
print("CUDNN Version:", torch.backends.cudnn.version())
if torch.cuda.is_available():
x = torch.rand(5, 5, device="cuda")
print("A random tensor on GPU:", x)
这段代码将检查 PyTorch 的版本、CUDA 是否可用、cuDNN 的版本,并尝试在 GPU 上创建一个随机张量。
如果这些步骤成功执行,并且没有错误,这表示你的 PyTorch 已经正确安装,并且能够利用 GPU 进行计算。
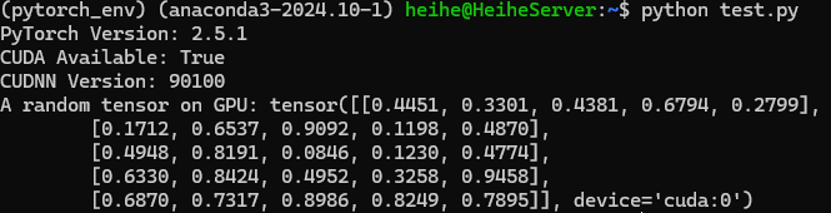
输出解释:
-
PyTorch Version: 2.5.1 - 这显示了当前安装的 PyTorch 版本。
-
CUDA Available: True - 这表明 PyTorch 能够识别并使用 CUDA,即 GPU 加速是可用的。
-
CUDNN Version: 90100 - 表示 cuDNN 版本为 9.1,这是用于深度学习的 NVIDIA GPU 加速库。
-
A random tensor on GPU - 展示了在 GPU 上成功创建并处理的随机张量,这验证了 GPU 正在被正确地用于计算。
(三)测试环境
正常情况下,下面的代码不会报错,并且输出各个版本号
import torch
print("PyTorch Version: {}".format(torch.__version__))
print("\nCUDA is available:{}, version is {}".format(torch.cuda.is_available(), torch.version.cuda))
print("\ndevice_name: {}".format(torch.cuda.get_device_name(0)))
输出如:
PyTorch Version: 2.6.0+cu124
CUDA is available:True, version is 12.4
device_name: NVIDIA GeForce RTX 4070 SUPER
(四)python 的魔法命令
感叹号 ! 可以在python环境中调用系统命令
1. 查看显卡信息
!nvidia-smi
Mon Jan 13 14:35:42 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 565.57.02 Driver Version: 566.03 CUDA Version: 12.7 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4070 ... On | 00000000:01:00.0 On | N/A |
| 56% 24C P8 5W / 220W | 855MiB / 12282MiB | 1% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 587 G /Xwayland N/A |
+-----------------------------------------------------------------------------------------+
2. 输出当前位置
!pwd
输出
/home/heihe/Machine_learning/pytorch教程
3. 计时模块
%%timeit 是一个用于 计时整个代码块运行时间 的 IPython 魔法命令。
它会自动多次运行代码块(默认 7 次)并输出平均运行时间和标准差。
非常适合用于性能评估和对比不同代码实现。
%%timeit
a = []
for i in range(10):
a.append(i)
输出
142 ns ± 0.954 ns per loop (mean ± std. dev. of 7 runs, 10,000,000 loops each)
%%time 测量整个代码块运行一次的时间(包括用户代码中的任何初始化、运算等)。
提供一次运行的详细时间信息,包括 CPU 时间 和 墙钟时间。
更适合测量单次运行的性能,尤其是对运行时间较长的代码块。
%%time
a = []
for i in range(1000000):
a.append(i)
CPU times: user 19.7 ms, sys: 30 ms, total: 49.7 ms
Wall time: 48.9 ms
(五)模型测试:ResNet18
ResNet18 是一种深度卷积神经网络架构,属于 ResNet(Residual Network)系列。
ResNet 用于解决随着网络深度增加导致的 梯度消失 和 梯度爆炸 问题,并获得了 ImageNet 图像分类任务的冠军。
ResNet18 是 ResNet 系列中的一个变体,其深度为 18 层,是 ResNet 的一种轻量级实现
残差块(Residual Block)
ResNet的关键创新是引入了 跳跃连接(Skip Connection)。- 传统的深度网络直接将输入传入卷积层,可能导致梯度在反向传播中逐渐消失。
ResNet通过跳跃连接,直接将输入绕过中间层传到输出,这样可以让梯度直接传播到前面的层,从而缓解梯度消失问题。
ResNet18 的网络结构(简化版)
| 层类型 | 输出尺寸 | 层参数 |
|---|---|---|
| 输入层 | 224x224 | 7x7 卷积,步幅 2,通道数 64 |
| 最大池化层 | 112x112 | 3x3 最大池化,步幅 2 |
| 残差模块 1 | 112x112 | 两个残差块,通道数 64 |
| 残差模块 2 | 56x56 | 两个残差块,通道数 128 |
| 残差模块 3 | 28x28 | 两个残差块,通道数 256 |
| 残差模块 4 | 14x14 | 两个残差块,通道数 512 |
| 全局平均池化层 | 1x1 | 无参数 |
| 全连接层 | 1x1 | 输出 1000 类别 |
Resnet的简单实现
import torchvision.models as models
resnet18 = models.resnet18(pretrained=True) # 加载预训练的 ResNet18 模型
# print(resnet18) # 输出网络结构
resnet18.fc = torch.nn.Linear(512, 10) # # 修改最后一层以适应自定义分类任务。假设有 10 个类别
# 定义输入
input_tensor = torch.randn(1, 3, 224, 224) # 输入尺寸为 224x224 的 RGB 图像
output = resnet18(input_tensor) # 前向传播
print(output.shape) # 输出张量的形状
输出应如下
torch.Size([1, 10])
(六)PyTorch 模块结构
安装好的PyTorch是一个庞大的python库,其中包含几十个模块,
这里我们来了解模块的构成,模块代码的位置,对应文档的位置。
从而帮助我们清楚地知道所用的PyTorch函数、模块都在哪里,是如何调用的。
查找pytorch的安装位置
import torch
torch_path = torch.__file__
print(torch_path)
/home/heihe/.pyenv/versions/anaconda3-2024.10-1/envs/pytorch_env/lib/python3.12/site-packages/torch/__init__.py
显示目录下的文件
import os
# 指定目录路径
directory = "/home/heihe/.pyenv/versions/anaconda3-2024.10-1/envs/pytorch_env/lib/python3.12/site-packages/torch"
# 列出文件和文件夹
for item in os.listdir(directory):
item_path = os.path.join(directory, item)
if os.path.isfile(item_path):
print(f"文件: {item}")
elif os.path.isdir(item_path):
print(f"文件夹: {item}")
文件夹: _dispatch
文件夹: mps
文件夹: func
文件夹: quantization
文件: _tensor_docs.py
文件: _size_docs.py
文件: serialization.py
文件: _linalg_utils.py
文件: _python_dispatcher.py
文件夹: lib
文件: _torch_docs.py
文件: _ops.py
文件夹: onnx
文件: torch_version.py
文件夹: testing
文件夹: compiler
文件夹: _awaits
文件夹: linalg
文件夹: jit
文件夹: profiler
文件夹: masked
文件: _tensor.py
文件: _lowrank.py
文件夹: _functorch
文件: version.py
文件夹: special
文件夹: fft
文件: _guards.py
文件夹: _inductor
文件夹: _strobelight
文件: overrides.py
文件: _tensor_str.py
文件夹: _library
文件: __config__.py
文件夹: autograd
文件: _jit_internal.py
文件: _vmap_internals.py
文件夹: utils
文件: random.py
文件: _custom_ops.py
文件夹: _numpy
文件夹: distributions
文件夹: _prims
文件夹: _C
文件夹: _custom_op
文件夹: _vendor
文件: _classes.py
文件夹: futures
文件夹: xpu
文件夹: include
文件夹: signal
文件: _utils.py
文件: functional.py
文件夹: cpu
文件: hub.py
文件夹: amp
文件夹: fx
文件: storage.py
文件夹: _higher_order_ops
文件: _storage_docs.py
文件: _compile.py
文件夹: _export
文件夹: share
文件: _namedtensor_internals.py
文件: py.typed
文件: return_types.py
文件: _VF.py
文件夹: bin
文件夹: _decomp
文件: _sources.py
文件夹: monitor
文件: _deploy.py
文件: return_types.pyi
文件夹: _logging
文件: library.py
文件夹: cuda
文件: _meta_registrations.py
文件夹: distributed
文件夹: backends
文件夹: ao
文件夹: _subclasses
文件夹: _prims_common
文件夹: __pycache__
文件: types.py
文件夹: optim
文件夹: contrib
文件: _streambase.py
文件夹: multiprocessing
文件: __init__.py
文件: _weights_only_unpickler.py
文件: __future__.py
文件夹: sparse
文件夹: _lazy
文件夹: export
文件夹: _refs
文件: _lobpcg.py
文件: _utils_internal.py
文件夹: _dynamo
文件: quasirandom.py
文件夹: mtia
文件: _C.cpython-312-x86_64-linux-gnu.so
文件: _VF.pyi
文件: _appdirs.py
文件夹: nn
文件夹: nested
文件夹: package
可以看到torch文件夹中有一系列子文件夹,我们平时常用的函数都包含在这些子文件夹中,下面将重点介绍一些。
- _pycache_
- 该文件夹存放python解释器生成的字节码,后缀通常为pyc/pyo。
其目的是通过牺牲一定的存储空间来提高加载速度,对应的模块直接读取pyc文件,而不需再次将.py语言转换为字节码的过程,从此节省了时间。从文件夹名称可知,它是一个缓存,如果需要,我们当然可以删掉它
- _C
- 这是辅助C语言代码调用的一个模块,该文件夹里存放了一系列pyi文件,
pyi文件是python用来校验数据类型的,如果调用数据类型不规范,会报错。
PyTorch的底层计算代码采用的是C++语言编写,并封装成库,供pytorch的python语言进行调用。
- include
- 这就是上面讲到pytorch许多底层运算使用的 C++代码 所存放的位置
在torch/csrc文件夹下可以看到各个.h/.hpp文件,而在python库中,只包含头文件,这些头文件就��在include文件夹下。
- lib
- 这是torch文件夹中最重要的一个模块,pytorch的内容几乎都在lib里面。 lib文件夹下包含大量的.lib .dll文件(分别是静态链接库和动态链接库),例如大名鼎鼎的cudnn64_7.dll(占435MB), torch_cuda.dll(940MB)。这些底层库都会被各类顶层python api调用。这里推荐大家自行了解什么是静态链接库和动态链接库。
- autograd
- 该模块是pytorch的核心模块与概念,它实现了梯度的自动求导,极大地简化了深度学习研究者开发的工作量,
- nn
- 这个模块的使用频率最高,搭建网络的网络层就在nn.modules里边。
- onnx
- pytorch模型转换到onnx模型表示的核心模块,进入文件夹可以看到大量的opset**.py, 这里留下一个问题,各版本opset是什么意思?有什么区别?
- optim
- 优化模块,深度学习的学习过程,就是不断的优化,而优化使用的方法函数,都暗藏在了optim文件夹中,进入该文件夹,可以看到熟悉的优化方法:“Adam”、“SGD”、“ASGD”等。以及非常重要的学习率调整模块,lr_scheduler.py。
- utils
- utils是各种软件工程中常见的文件夹,其中包含了各类常用工具,其中比较关键的是data文件夹,tensorboard文件夹,这些工具都将在后续章节详细展开。
以上是torch库,针对不同的应用方向,pytorch还提供了torchvision、torchtext、torchaudio等模块,
这里以 torchvision 为例,找到其目录
import torchvision
torch_path = torchvision.__file__
print(torch_path)
/home/heihe/.pyenv/versions/anaconda3-2024.10-1/envs/pytorch_env/lib/python3.12/site-packages/torchvision/__init__.py
- datasets
- 这里是官方为常用的数据集写的数据读取函数,例如常见的cifar, coco, mnist,svhn,voc都是有对应的函数支持,可以方便地使用轮子,同时也可以学习大牛们是如何写dataset的。
- models
- 这里是宝藏库,里边存放了经典的、可复现的、有训练权重参数可下载的视觉模型,例如分类的alexnet、densenet、efficientnet、mobilenet-v1/2/3、resnet等,分割模型、检测模型、视频任务模型、量化模型。这个库中的模型实现,也是大家可以借鉴学习的好资料,可以模仿它们的代码结构、函数、类的组织。
- ops
- 视觉任务特殊的功能函数,例如检测中用到的 roi_align, roi_pool,boxes的生成,以及focal_loss实现,都在这里边有实现。
- transforms
- 数据增强库,相信99%的初学者用到的第一个视觉数据增强库就是transforms了,transforms是pytorch自带的图像预处理、增强、转换工具,可以满足日常的需求。但无法满足各类复杂场景,因此后续会介绍更强大的、更通用的、使用人数更多的数据增强库——Albumentations。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
print("your torch library in here:{}".format(torch.__path__))
print("your nn library in here:{}".format(nn.__path__))
print("your optim library in here:{}".format(optim.__path__))
# print(type(DataLoader), type(nn))
# print("your DataLoader library in here:{}".format(DataLoader.__path__)) # 思考:这行代码为什么报错?
# print("your Dataset library in here:{}".format(Dataset.__path__)) # 思考:这行代码为什么报错?
输出:
your torch library in here:['/home/heihe/.pyenv/versions/anaconda3-2024.10-1/envs/pytorch_env/lib/python3.12/site-packages/torch']
your nn library in here:['/home/heihe/.pyenv/versions/anaconda3-2024.10-1/envs/pytorch_env/lib/python3.12/site-packages/torch/nn']
your optim library in here:['/home/heihe/.pyenv/versions/anaconda3-2024.10-1/envs/pytorch_env/lib/python3.12/site-packages/torch/optim']