第 1 课:网络架构
(一)局域网络结构
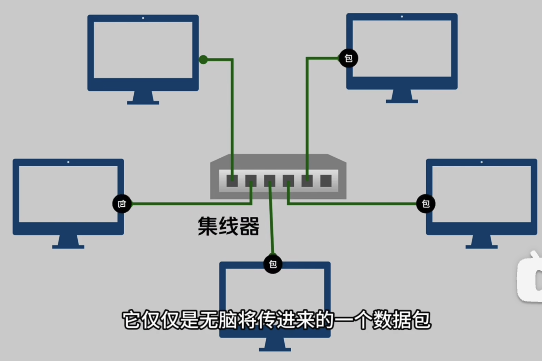
1. 集线器
如果每根电脑都用电线连接,在电脑数量激增时,就会变得十分混乱。
为了解决这个问题,使用了一个“集线器”, 对消息统一做转发
2. 交换机
集线器的问题在于任意一个端口收到的消息都会被广播到所有端口,也就产生了两个问题
- 接收方不知道这个消息是不是发给自己的
- 没办法 1对1 通话
因此我们给每个主机加上 Mac 地址,并给发送的数据包标记 源mac 和 目标 mac
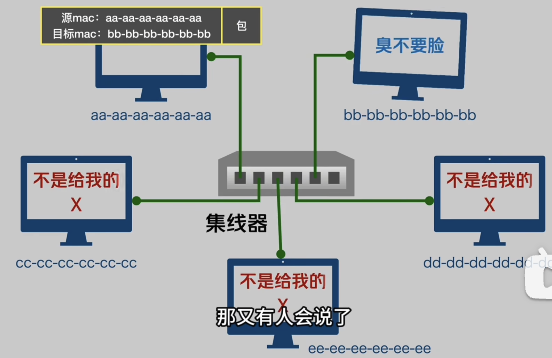
但是这样还是存在问题,就是非目标主机还是可以收到数据包,可以选择是否接受。
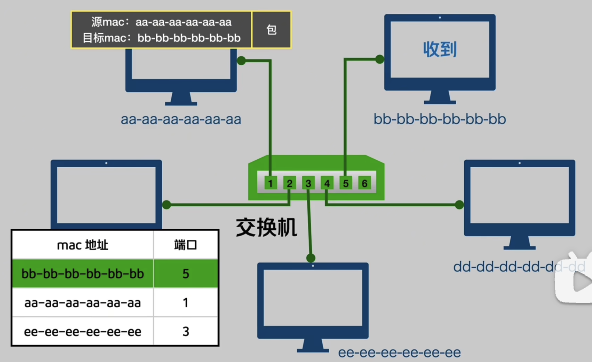
因此我们把集线器换成交换机,其内部维护一样 Mac 地址表,给每个端口绑定一台主机的 mac 地址,数据统一由交换机来决定出出入。这样其他主机就不会收到不该收到的消息了。
不过要注意的是,开始的时候交换机内部还没有建立这张 Mac 地址表。因此刚开始的时候和集线器没有区别,但是交换机会在收到数据包后记录对应的端口号和 mac 地址,来更新 Mac 地址表来进行学习。
但是随着电脑越来越多,交换机的端口也会逐渐不够用,因此我们需要多台交换机,并把交换机连接起来
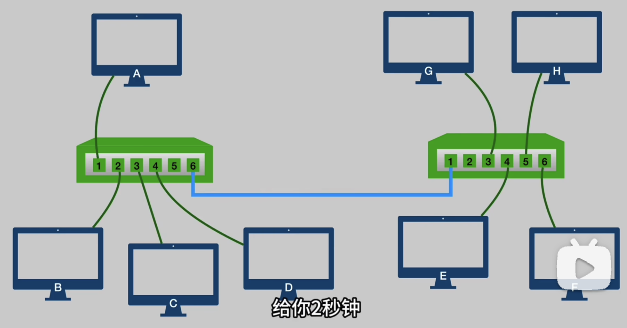
此时左边这台交换机维护的Mac 地址表就是:
| Mac 地址 | 对应端口 |
|---|---|
| AAA-AAA-AAA-AAA | 1 |
| BBB-BBB-BBB-BBB | 2 |
| CCC-CCC-CCC-CCC | 3 |
| DDD-DDD-DDD-DDD | 4 |
| EEE-EEEE-EEE-EEE | 6 |
| FFF-FFF-FFF-FFF | 6 |
| GGG-GGG-GGG-GGG | 6 |
| HHH-HHH-HHH-HHH | 6 |
右边的交换机也维护一张类似的表,这样如果是 A -> E 的表,就会以如下路径去发送
A -> (1口)左交换机(6口) -> (1口)右交换机(4口) -> E
3. 路由器
只用交换机的架构仍然有问题,就是随着每张 Mac 地址表仍然需要记录所有电脑的 Mac 地址,随着电脑数量激增,这张表会变得非常大!因此我们在中间添加一台路由器,路由器的每一个端口都有独立的 Mac 地址。
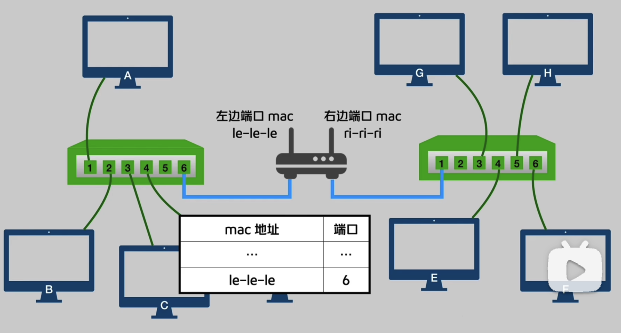
那么从 A-> E 的架构就变成了:
A -> (1口如)交换机,找不到 E 设备(6口出)-> (le口)路由器
但是问题就出现了,路由器怎么知道 E 设备在哪一个口呢?因此我们就要引入 IP 地址的概念。
我们可以看到 左边的IP地址全是 192.168.0.x,右边的全都是 192.168.1.x,分别对应路由器的左端口和右端口。
这样一来,A->C 的请求链路中,根据 D 的IP 192.168.1.44 路由器就知道要发向右边的端口
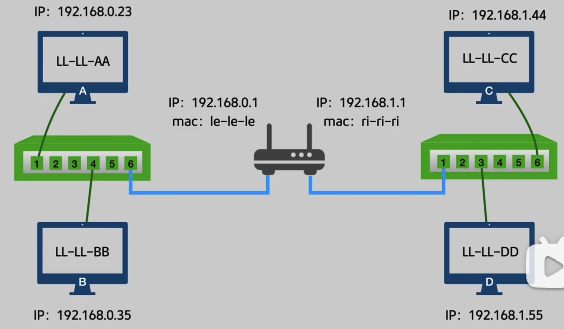
此时数据包也就需要带有两个头部信息了
在 A - 路由器 的过程中包如下:
| 数据链路层头部 | 网络层头部 | 数据包 |
|---|---|---|
| 源 mac: LL-LL-AA | 源 IP:192.168.0.23 | |
| 目标 Mac:le-le-le | 目标 IP:192.168.1.44 |
经过路由器时,路由器会把包改成:
| 数据链路层头部 | 网络层头部 | 数据包 |
|---|---|---|
| 源 mac: LL-LL-AA | 源 IP:192.168.0.23 | |
| 目标 Mac:LL-LL-CC | 目标 IP:192.168.1.44 |
现在的 A -> C 的完整请求链条就变为:
A(192.168.0.23)
|
v (1口)
交换机发现目标IP 不在同一子网,因此发送给路由器端口
| (6口)
v (左口)
路由器收到,发往对应的子网端口
| (右口)
v (1口)
交换机
| (6口)
v
C(192.168.1.44)
注意:
-
在 A 上需要设置默认网关,也就是路由器的位置。
-
路由器内部有一张路由表,记录 子网和 对应端口 的映射关系
-
第一次建立好网络发送数据时,无论是否经过路由器,都是根据 IP 而不是 Mac 地址的。
-
在第一次通信(A-B)成功后,电脑A上会在 ARP表 中把对应的 IP 和 Mac 地址关联起来
多台交换机连接在一起组成一个大的“广播域”,也就是说广播(如 ARP)还是会跨交换机传播,只有路由器才能隔离广播域。
子网掩码
子网掩码的作用是用来判断两个 IP 是否在同一个子网中。逻辑是“IP地址 & 子网掩码”。

其中,判断两个 IP 地址是否在同一个子网,取决于它们与相同子网掩码做按位与运算(bitwise AND)的结果是否相同。
IP地址: 192.168.0.23 -> 二进制:11000000.10101000.00000000.00010111
子网掩码: 255.255.255.0 -> 二进制:11111111.11111111.11111111.00000000
按位与结果:192.168.0.0 -> :11000000.10101000.00000000.00000000
网络层(IP协议)本身没有传输包的功能,包的实际传输是委托给数据链路层,也就是以太网终端交换机来实现的。
目前涉及到的三张表:
| 表名 | 位置 | 映射对象 |
|---|---|---|
| Mac 地址表 | 交换机 | Mac 地址和对应端口 |
| 路由表 | 路由器 | 子网范围 和 对应端口 |
| ARP 缓存表 | 电脑 和 路由器 | IP 和 Mac 地址 |
4. DHCP 服务器
上面我们讲了 局域网内是如何通信的,接下来我们要思考一个问题:
现在一台新的主机连入了这个网络中,他的 IP 是如何被自动分配的呢?
DHCP(dynamic host configure protocal),动态主机配置协议,用于自动分配IP地址,避免IP冲突,提高地址利用率
协议:就是规则,是有漏洞的
地址池/作用域:比如 10.0.0.1-10.0.0.254,地址池里除了IP之外还有子网掩码,网关,DNS,租期
DHCP原理:称为 DHCP租约过程,分4个步骤
-
客户机发送
DHCP Discovery广播包,寻找DHCP服务器客户机广播请求IP地址(包含客户机的唯一标志,MAC地址)
-
服务器响应
DHCP Offer广播包多台服务器收到请求后,响应提供IP地址(但无子网掩码,�网关等参数)
-
客户机发送
DHCP Request广播包客户机收到最先到达的响应,然后广播请求 发出这个响应的服务器 提供更多参数,这也是拒绝了其他的服务器
-
服务器发送
DHCP ACK广播包(ACK是acknowlege,确认)服务器确定了租约,并提供网卡详细参数和租期。在租期内,客户机开关机一直都会使用这个IP
攻击方法:
- 把黑客电脑部署成
DHCP 服务器,接受到Discover请求后比DHCP服务器快一步返回Offer广播包。这样客户机就会去连接黑客电脑提供的IP,从而上不了网。 - kali 系统伪造大量的 MAC 地址,大量地发起
Discovery请求,把DHCP的IP地址耗光
防御方法:
- 在交换机(管理型)上设置只有特定的一台DHCP服务器的接口可以发出Offer数据包
- 用管理型交换机,进行MAC地址绑定,这样一台客户机就只能使用一个MAC地址
绑定方法:
-
静态绑定:拔网线之前绑定
-
动态绑定:拔不拔网线都绑定
DHCP续约
客户机 从获取地址开始,就不再和DHCP交流。但是在租期达到1/2时,客户机会再次发送DHCP Request包
注意:续约是从当前开始续约,不是当前租期结束了再开始续约
续约请求一定是成功的。对于公共场合,租期要短一点。私有场合租期可以长一点。
特殊情况
- 若在 50% 续约的时候DHCP服务器无响应,则在续约事件 87.5% 再次请求,若仍然无响应则自动释放当前IP,重新请求IP地址。
- 如果重新请求失败,则网卡自动分配
169.254.x.x网段,因此还可以保证局域网内所有断线客户机互相交流。这个地址全球统一的无效地址,用于内网通信。
(二)IP地址
上面我们讲了局域网内部的通信,那么我们平时是如何上网的呢?
我们假设我们刚买了一台新电脑和新路由器,建立了一个全新的局域网。
那么这台电脑A(192.168.0.23)要发送数据包给 142.250.72.68(www.google.com 的一个公网 IP),是如何找到这个公网IP 地址的呢?
C/S架构:客户端对服务器
B/S架构:多个服务器映射到一个服务器上对外开启web服务(堡垒机)
1. 网段
在上面我们已经学习了IP地址: 一段网络编码,二进制编码 xxxxxxxx.xxxxxxxx.xxxxxxxx.xxxxxxxx
转化成10进制后的范围:0-255
局域网通信规则:必须在同一网段(网络)内才可以互相通信
因此IP地址的 前3位/前2位/前1位 代表网段,剩下的代表主机的编码
以前三位为网段为例:105.2.3.1 这里 105.2.3 代表这个局域网,.1 代表某一台机器
2. IP分类
IP地址被划分为3类,根据第一位判断
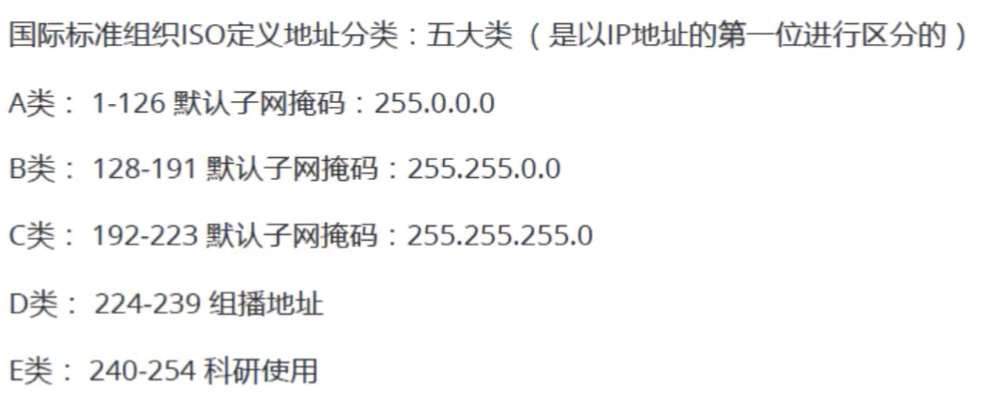
注意:
-
组播地址:本来是服务器向各个IP发送数据,现在交给组播地址发送
-
个人只能设置第一位为ABC类,DE类会显示无效。
-
ABC类的子网掩码允许修改(不按照图中的子网掩码)
-
剩下的主机地址不能全为0!!因为那是网段地址!比如
105.1.1.0可能是无效的,因为他可能是一个网段地址。 -
剩下的主机地址不能全为255!因为那是广播地址。比如向
105.1.1.255发送信息 ,实际上会向105.1.1.0网段的所有主机发送数据 -
255.255.255.255不能用,因为那是全球广播地址 -
127开头的代表一些特殊地址:127.0.0.1本地回环地址,一般用于测试(注意没有经过交换机。在机内进行)
3. 树形网络结构
我们要注意,IP 这个东西其实是虚拟的,也就是可以手动修改的,不是和 Mac地址 一样烧录在硬件上的。
我们之前讲过,一个路由器可以管理多个子网如 192.168.1.xxx 和 192.168.0.xxx。任何在这个子网中的设备想要上网,数据包都必须要先经过这个路由器,路由器接受子网中传来数据的端口叫做 网关,或者 对内网关,专业术语叫 LAN口 IP,它是子网主机眼中的 “默认网关”,当主机判断某个目标 IP 不属于当前子网时,数据包就会转发给路由器的 LAN 口。而路由器的实际作用其实是根据 目标IP 和 子网掩码 来计算,决定要把数据包转发到哪一个子网。数据包进入子网后,后续的工作由交换机来进行。
简而言之,路由的作用其实就只是支持数据包在子网之间传递,真正根据数据包目标IP 发送到指定机器的其实是 交换机。实际上传输路径是 路由器根据 IP 决定“转发到哪个子网”,交换机根据 MAC 地址决定“发给哪个具体主机”。
层级 处理依据 作用描述 路由器(3层) IP 子网之间转发,跨子网路由 交换机(2层) MAC / IP 同子网内局部转发 但是现在很多家用 WIFI 路由器都集成了路由器和交换机的功能,因此兼具两者的功能。
互联网其实是一个树形结构,一个路由器本身其实也是作为一个设备处于一个更大的局域网中,路由器对外收发信息的端口叫做 对外网关,专业术语叫 WAN口 IP,是更高一级的路由器眼中的“内部主机”。如下图所示,路由器 B、C 各自创建了两个子网 192.168.1.xxx 和 192.168.0.xxx,但是他们同时自身也处于一个更大的子网 192.168.0.xxx 中。
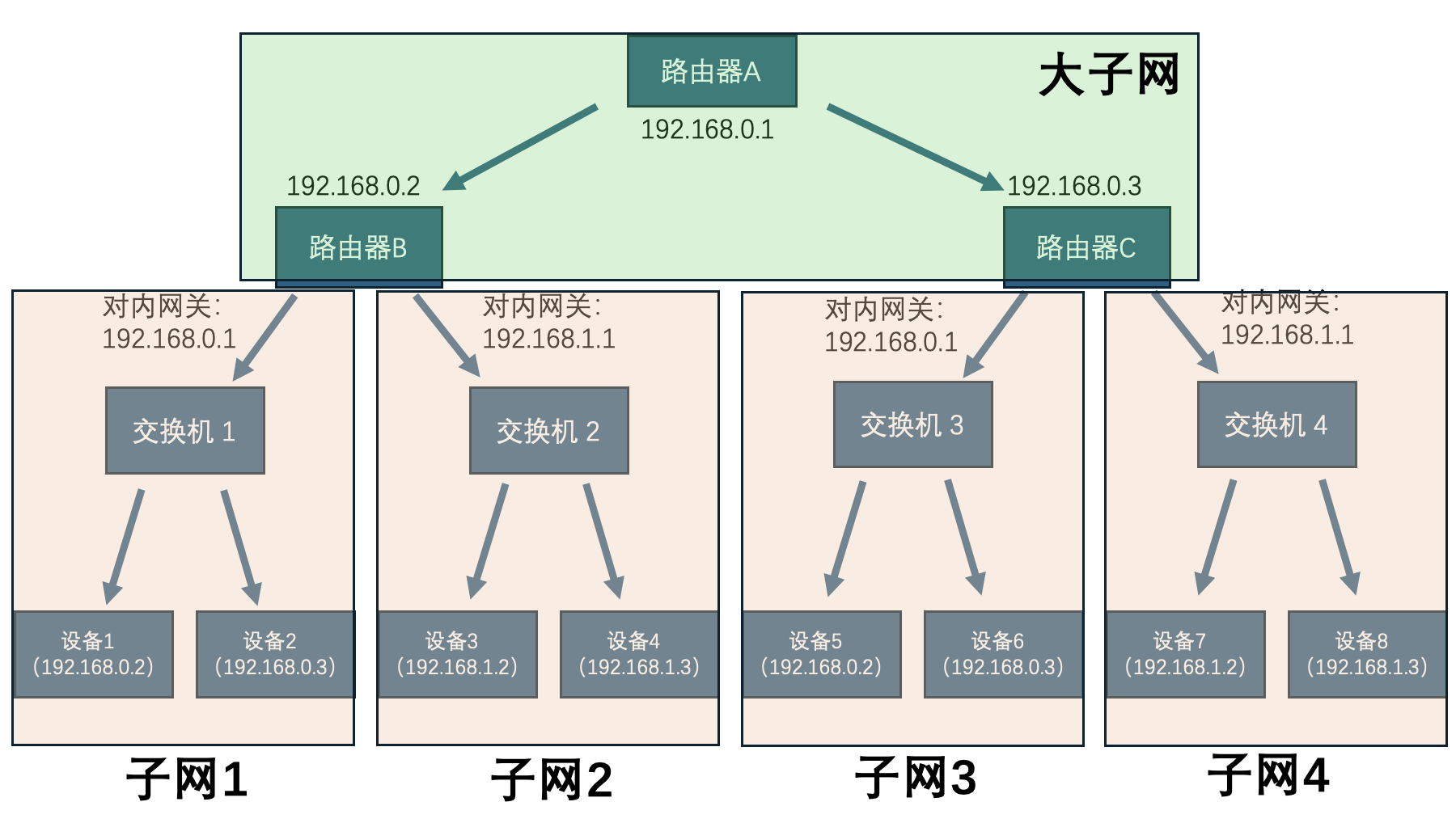
我们买过来一个路由器,不可能虚空接受信号,需要拉上网线接入光纤,连接上互联网运营商(ISP)的线路,比如中国移动、中国电信等等。此时这个路由器也就已经身处于上图中的所谓”大子网“之中了,不过此时上层的不是 路由器A,而是 运营商(ISP)。
一个新的路由器接入 ISP 提供的网络时,需要进行 拨号上网,也就是输入 在 运营商营业厅 注册的账号密码 以验证身份。这个步骤就好像我们连入一个新 wifi 时,需要输入密码。
运营商收到 路由器发送的请求联网的数据包 后,校验账号密码,验证身份通过(比如你刚刚在营业厅购买了家庭包月带宽套餐),于是就给这台路由器分配一个IP地址(可能是公网 IP,也可能是运营商内网 IP,这里暂时只当成内网 IP)。此后这台路由就使用这个 IP 去和 ISP 进行通信,所有数据包都经过运营商转发。
注意:ISP 给路由器分配的这个内网 IP 不是固定的,而是使用了 DHCP 协约,定时更新。
那么问题又来了:
新路由器刚接入 ISP 提供的局域网络时,是如何找到 ISP 提供服务的 IP+端口 的?
你可以理解为两个不同的场景:
| 场景类型 | 常见名称 | 网络类型 | 路由器如何发现 ISP 节点(即“下一跳”)? |
|---|---|---|---|
| 场景1 | DHCP 自动获取 IP | 动态拨号 / DHCP | 使用广播 DHCP Discover 请求 |
| 场景2 | PPPoE 拨号上网 | ADSL / 光猫拨号 | 使用点对点协议,通过广播发现 PPPoE Access Concentrator(接入服务器) |
场景一:DHCP 获取动态 IP
现在大部分光猫 + 路由器组合使用这种方式,尤其是“桥接光猫 + 家用路由器”的架构。
ISP 在你小区、楼层、路由器接入口附近的交换机中运行了一个 DHCP 服务器;
只要你物理连接到 ISP 的网络(比如光纤插入 WAN 口),就可以通过 DHCP 广播发现服务。
这种情况下新路由器不需要“知道”上级服务节点的 IP,它是通过局域网内的 DHCP 广播机制 自动发现的。
场景二:PPPoE 拨号上网
适用于一些旧式拨号上网模式(比如 ADSL)、或你家是“光猫桥接 + 路由器拨号”这种架构。
PPPoE是Point-to-Point Protocol over Ethernet;- 是一种点对点封装协议,建立一个“虚拟拨号链路”;
- 你在路由器后台填写账号密码(ISP 营业厅提供);
工作过程(简化为三步):
- 发现 ISP 提供的 PPPoE Access Server(AC)
- 路由器发送 PPPoE Active Discovery Initiation(PADI)广播;
- 查找网络中有没有 PPPoE 接入服务器;
- ISP 返回 PPPoE Offer
- 表示“我是认证服务器,你可以试试连我”
- 开始拨号会话:PPPoE Session
- 输入账号密码进行 PAP/CHAP 验证;
- 验证成功 → ISP 分配一个公网 IP 或内网 IP
这个过程同样也是基于广播的,因此也不需要事先知道 IP 地址:
就像你刚走进一家酒店(网络):
- DHCP 就是前台喊“有空房间吗?给我一个!”(服务发现 + 房间号)
- PPPoE 是你得先“拨打前台电话,报身份证号和密码”才能入住(账号验证)
4. 公网 IP
公网 IP(Public IP Address) 是全球唯一的 IP 地址,由 互联网管理机构(IANA) 分配给各个 ISP(互联网服务提供商),用于在整个互联网中唯一标识一台设备。
| 公网 IP 特点 | 局域网 IP 特点 |
|---|---|
| 全球唯一 | 局域网内唯一,多个局域网可重复使用 |
| 可以直接访问互联网 | 无法直接访问互联网 |
| 由 ISP 分配 | 由 DHCP(路由器)自动分配 |
| 示例:8.8.8.8(Google) | 示例:192.168.0.23、10.0.0.2 |
(三)公网 IP 访问
还是回到上面那个问题
我们假设我们刚买了一台新电脑和新路由器,建立了一个全新的局域网。
那么这台电脑A(192.168.0.23)要发送数据包给
142.250.72.68(www.google.com 的一个公网 IP),是如何找到这个公网IP 地址的呢?
当我们说“找到目标”,其实本质是在回答:
- 数据包如何在“路由器层层转发”中,最终抵达一个全球唯一的公网 IP 所在的服务器?
- 在初次访问 vs 重复访问时,这个路径是否会不同?
整体流程分解为 4 层:
| 阶段 | 层级 | 描述 |
|---|---|---|
| 1 | 局域网内(本地) | 主机构建数据包,交给网关(路由器) |
| 2 | 边缘出口 | 路由器转发至运营商(ISP)的更上层路由器 |
| 3 | 互联网骨干网 | 多个路由器根据 BGP协议 路由表,逐跳转发直到目标IP所属的子网 |
| 4 | 目标服务器接收 | IP 路由转发到目标公网 IP 的网络,服务器响应 |
步骤一:主机 → 本地
主机 A 用 子网掩码 判断目标 142.250.72.68 不在同一子网(与默认网关不同子网),于是将数据包发往默认网关(比如 192.168.0.1,对应路由器的 LAN口)。数据包结构如下:
| 层 | 内容 |
|---|---|
| 链路层 | 源 MAC:主机A,目标 MAC:路由器 |
| 网络层 | 源 IP:192.168.0.23,目标 IP:142.250.72.68 |
| 传输层 | TCP 或 UDP 端口,应用数据 |
如果主机是第一次启动、没有 ARP 表,它会先通过广播 ARP Request 得到默认网关的 MAC 地址(有线连接或者无线��信号都可以)
步骤二:本地 → ISP
路由器检查路由表,判断目标 IP 142.250.72.68 是否在自己所管理的子网内 => 不在
于是路由器通过 WAN口,把这个访问请求发送给上一级路由器的 LAN口(默认网关 default route),通常是 ISP 分配的出口路由器。
当目标 IP 无法匹配任何具体路由条目时,数据包会被转发到
0.0.0.0/0-> 上级网关的公网 IP(比如114.114.114.1)
在一个局域网的路由器上,人为配置一个子网(如静态路由或子接口),使它的网段与某个真实公网 IP 所在网段重合。
结果是:
- 路由器会认为目标公网 IP 是“本地子网的一部分”
- 就不会发给默认网关(公网出口),而是直接丢到局域网接口
- 最终可能发给一个局域网中的设备伪装成该公网服务器
这就是一个典型的:静态路由劫持 + 子网重定义
但是 不会影响 DNS 域名解析,除非你同时劫持 DNS,否则:
ping www.google.com
→ 仍会解析为真实的 Google IP,然后触发你的静态路由规则
而且 HTTPS 会被识破,因为证书是为 *.google.com 签发的,局域网中的假服务器不可能拥有合法证书,因此浏览器会立即报错(证书不可信),除非你配合伪造 CA + 根证书(MitM 专业手法)
步骤三:ISP→互联网核心
我们称一个 ISP、云服务商、大学网络 这种由一个或多个 IP 网络组成的 单一管理单位 为一个自治系统 (AS)
每个 AS 都有唯一编号(ASN),如:
| 网络主体 | AS 号 |
|---|---|
| AS15169 | |
| Cloudflare | AS13335 |
| 中国电信 | AS4134 |
| 中科大 | AS559 |
各个 AS 之间不再是树形结构,而是星形拓扑结构,或更一般地说,是图结构。用通信电缆直接连接的两个 AS 被称为邻居 AS,他们之间可以直接传递数据。
比如现在有 5 个 AS,每个 AS 都维护着几个 公网 IP 网段,正如每个路由器都维护着几个内网 IP 网段一般,这个的专业名称叫 通告(Advertise)
AS 1 → 通告:1.1.0.0/16
AS 2 → 通告:2.2.0.0/16
AS 5 → 通告:5.5.0.0/16
`/16,即:,其余位是主机号**
我们知道 IPv4 的一位是 0-256,需要 8 位二进制表示,因此一个IP 是 32 位。/16 是CIDR(无类域间路由)表示法,表示前 16 位是网络号,固定不变。后 16位可变 ,因此这个 AS 管理的可用IP 地址为 = 65536 个 IP 地址
例如 100.64.0.0/10 的完整 IP 范围:100.64.0.0 ~ 100.127.255.255。这个 IP 段是专门为**大型 NAT 网络(CGNAT)**保留的。
每个 AS 都会吧自己维护的 IP 网段定向通告(route advertisement)给自己的邻居 AS,因此每个 AS 内部都会维护着一张表。
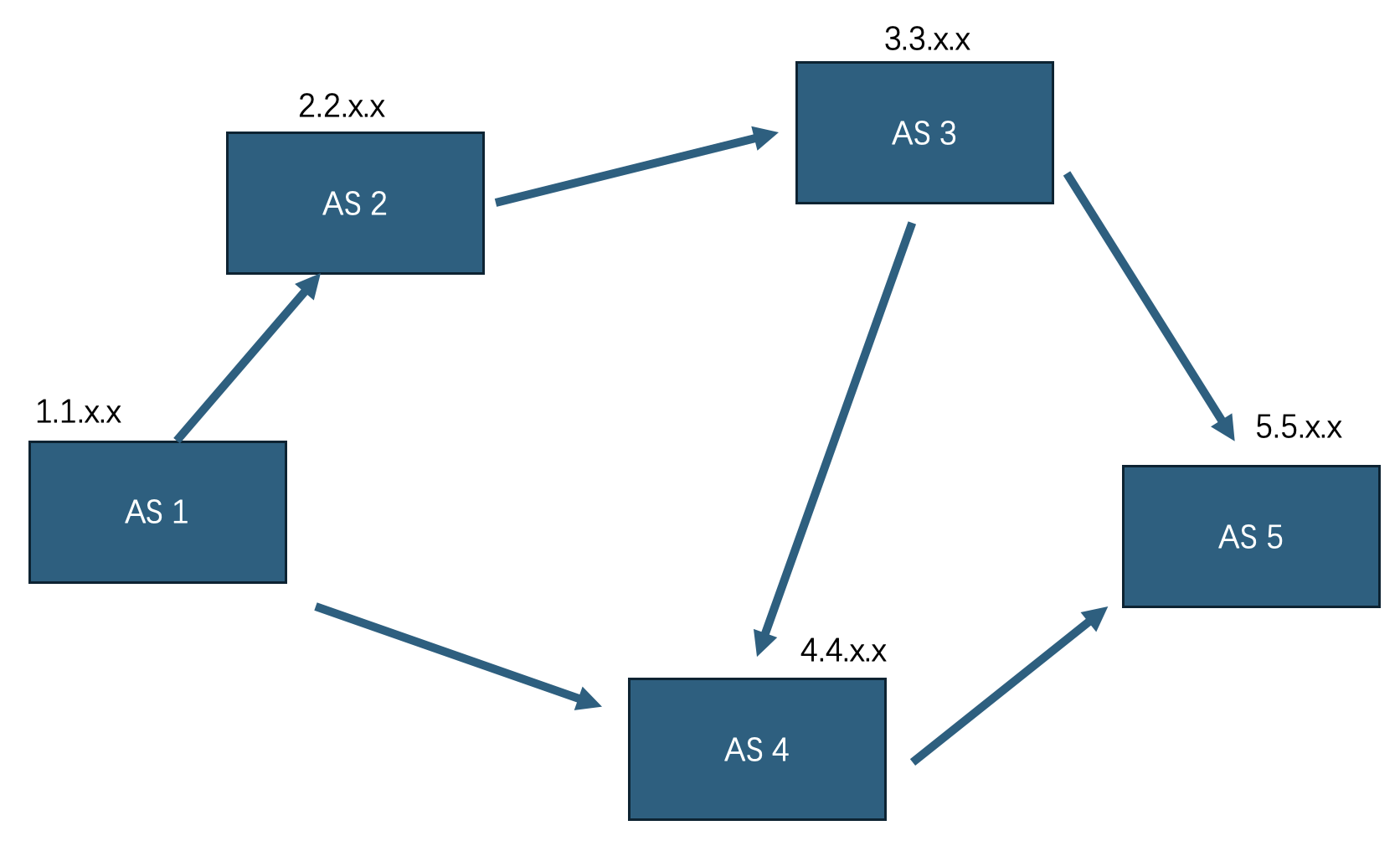
例如上图中 AS 5 拥有 IP 段 5.5.0.0/16,AS 5 将这个前缀通告给连接的 AS 3 和 AS 4
AS 3 收到这个前缀 → 将 AS5 加入 AS Path,生成记录:
前缀:5.5.0.0/16
来自:AS 5
AS Path:5
如果它决定向 AS 2 继续通告,会形成:
前缀:5.5.0.0/16
AS Path:3 5
AS 2 又转发给 AS 1,就形成:
AS Path:2 3 5
最终,AS 1 将会知道:要访问 5.5.0.0/16 网段,可以走路径:1 → 2 → 3 → 5
这个信息会被保存在 AS 1 的 BGP 路由表中。因此 AS 1 的 BGP 路由表 会保存 3 个路径:
| 路由前缀 | AS Path | 下一跳 |
|---|---|---|
| 5.5.0.0/16 | 4 → 5 | AS 4 |
| 5.5.0.0/16 | 2 → 3 → 5 | AS 2 |
| 5.5.0.0/16 | 2 → 3 → 4→ 5 | AS 2 |
然后,AS 1 会根据 路径选择规则(BGP Decision Process) 选择最优路径。因此 AS 1 会选第一条路径(因为路径更短)
优先级如下(常用):
Local Preference(本地手工策略) → 越大越优先
Shortest AS Path(AS 路径最短) → 你图中最常见的选择标准
Origin Type → 更可信来源优先
MED(Multi Exit Discriminator) → 低者优先
eBGP > iBGP(跨 AS 优于内部 AS)
Router ID 小者优先
可以手动限制:若 AS4 设置了如下 BGP 策略(比如 route-map):
deny 5.5.x.x from neighbor AS3→ 那么 AS4 就会拒收来自 AS3 的前缀。
这种策略常见于运营商之间的“谷底传输屏蔽”(valley-free routing)或 peering-agreement 限制。
上面我们提到的 BGP(Border Gateway Protocol) 是“边界网关协议”,是目前互联网上唯一运行的 外部网关协议(EGP)
回到之前的问题中,现在上层 ISP 的核心路由器收到数据包后,要找的公网 IP是 142.250.72.68,在之前 AS15169(Google)已经广播告诉 AS4134(中国电信) 142.250.0.0/16 这个网段属于 Google,因此 ISP 中国电信 的路由器从 BGP 路由表判断这个 IP 段属于Google,找到匹配的 下一跳自治系统(Next Hop AS) 和物理链路。
然后这个数据包被转发到下一跳对应的出口端口,重复此过程,直到达到 Google 的网络(AS15169)
| 路由前缀 | 下一跳 AS | 路径(AS Path) |
|---|---|---|
| 142.250.0.0/16 | AS15169 | AS4134(中国电信核心路由器) → AS3356(美国骨干网) → AS15169(Google) |
这时每个核心路由器都有自己完整的全局路由表,可以转发到目标 IP 所在的网络段。
BGP 的主要字段/机制
字段/机制 说明 AS Path 所有经过的 AS 编号组成的路径列表,越短越优先 Next Hop 下一跳 IP 或 AS Prefix 通告的 IP 段,如 142.250.0.0/16MED 多出口区分度量,用于在多个路径之间选择 Local Pref 本地首选值,值越高越优先 COMMUNITY 附加信息标签,用于策略控制 Withdraw 当一个前缀不可达时发出的撤销通告
AS3 AS4 AS5 形成了一个回环,这个 BGP path 会无线累加吗?不会,因为BGP 本身设计为:
“只要你收到的通告中 AS Path 不包含自己,就继续传下去。”
因此 AS3 收到来自 AS5 的通告:
5.5.x.x via AS Path: 5
它向 AS2、AS4 通告新的路径:
5.5.x.x via AS Path: 3 5
AS4 可能会向 AS5 通告这条路线,但是 AS5 发现自己已经位于这条线路当中,因此就不会接受这条通告
BGP 路由表(Routing Information Base, RIB)存储结构:不是图结构,而是「路径项集合」,结构如下
目的前缀 → 多个路径项(AS Path、Next Hop、优先级等)
例如:
5.5.0.0/16:
- Path A: AS Path = 3 5, Next Hop = IP_A, LocalPref = 100
- Path B: AS Path = 2 3 5, Next Hop = IP_B, LocalPref = 80
- Path C: AS Path = 4 5, Next Hop = IP_C, LocalPref = 120 ✅选用
你可以把 BGP 路由表理解为一个字典
Key:IP 前缀(目的地)
Value:到达该前缀的所有路径记录(AS Path + 属性)
BGP 没有保存“通用拓扑图”,因为它只关心“到哪去”、“怎么去”。
截至 2025 年初 全球已注册 AS 数量约 75,000+,公共前缀数量(IPv4)约 1,000,000+,每个活跃 AS 之间至少存在 间接可达性,但并不会全部建立 Peer 关系。因此每增加一个节点或者边,不是指数增长,但确实是爆炸性线性增长(Super-linear)
而之所以不记录整个图数据,是因为:
- 扩展性问题:如果维护 AS 拓扑图,每个节点要存下整个互联网结构,太大!
- BGP 不关心“任意 AS 之间的可达性”,而只关心“我能不能到达某个前缀”
- 策略灵活性:全图结构下不易实现策略过滤(比如拒绝某路径、优先某路径)
像中国电信(AS4134)这样的国家级运营商,几乎访问了全球所有公网 IP,这种叫做 BGP full table,大小大约为:
| 类型 | 数量级(估计值) |
|---|---|
| IPv4 前缀数 | 约 1,100,000+ 条前缀(百万级) |
| IPv6 前缀数 | 约 200,000+ 条前缀(不断增长) |
| AS Path 数量 | 每个前缀可带 2~3 条路径(成倍增长) |
| RIB 总条目 | 约 200~300 万 条路径项(可达) |
| 内存占用(纯 BGP) | 2GB~10GB+(取决于实现和细节) |
| 内存占用(含策略) | 通常 几十 GB(含路由策略、社区、标记) |
中国电信等运营商会用策略压缩 RIB → FIB,提升转发效率。
| 名称 | 作用 | 大小关系 |
|---|---|---|
| RIB(Routing Info Base) | 所有学到的前缀路径(含候选) | 更大 |
| FIB(Forwarding Info Base) | 实际用于转发的一条最佳路径 | 更小(压缩) |
-
BGP full table 实例分析(从 real-world dump 中看结构)
安装工具
# 安装 bgpdump sudo apt install bgpdump # 解码 RIB 文件 bgpdump -m rib.20250923.0800.bz2 | grep '5.5.0.0/16'数据来源:RouteViews + RIPE RIS
这些是全球主流 BGP 数据采集项目,采集了来自多个运营商的 完整 BGP 表(Full Table) 和通告日志(Update)
示例内容:
BGP_TABLE_DUMP2 1659363457
PREFIX: 5.5.0.0/16 # 路由前缀
ORIGIN_AS: 15169
AS_PATH: 6453 3356 15169 # 访问路径(从出口向入口读)
NEXT_HOP: 192.0.2.1 # 下一跳 IP 地址(邻居)
COMMUNITY: 3356:2000 6453:100 # 社区标签(路由策略元数据)
MED: 100
LOCAL_PREF: 100 # 本地优先级(路径决策依据)
-
BGP looking glass 工具实战(查看真实互联网路径)
使用全球公开的“远程 BGP 路由器”查看 从不同国家/AS 出发的路径,实现路径追踪、路由健康监测。
常用站点推荐
站点 入口 RIPE Atlas Looking Glass https://stat.ripe.net Hurricane Electric https://lg.he.net BGP.Tools https://bgp.tools NTT Communications https://www.bgpview.io/as2914 Cloudflare Radar https://radar.cloudflare.com 例如: Hurricane Electric(HE)执行的一次 真实 Traceroute 路径探测 的结果
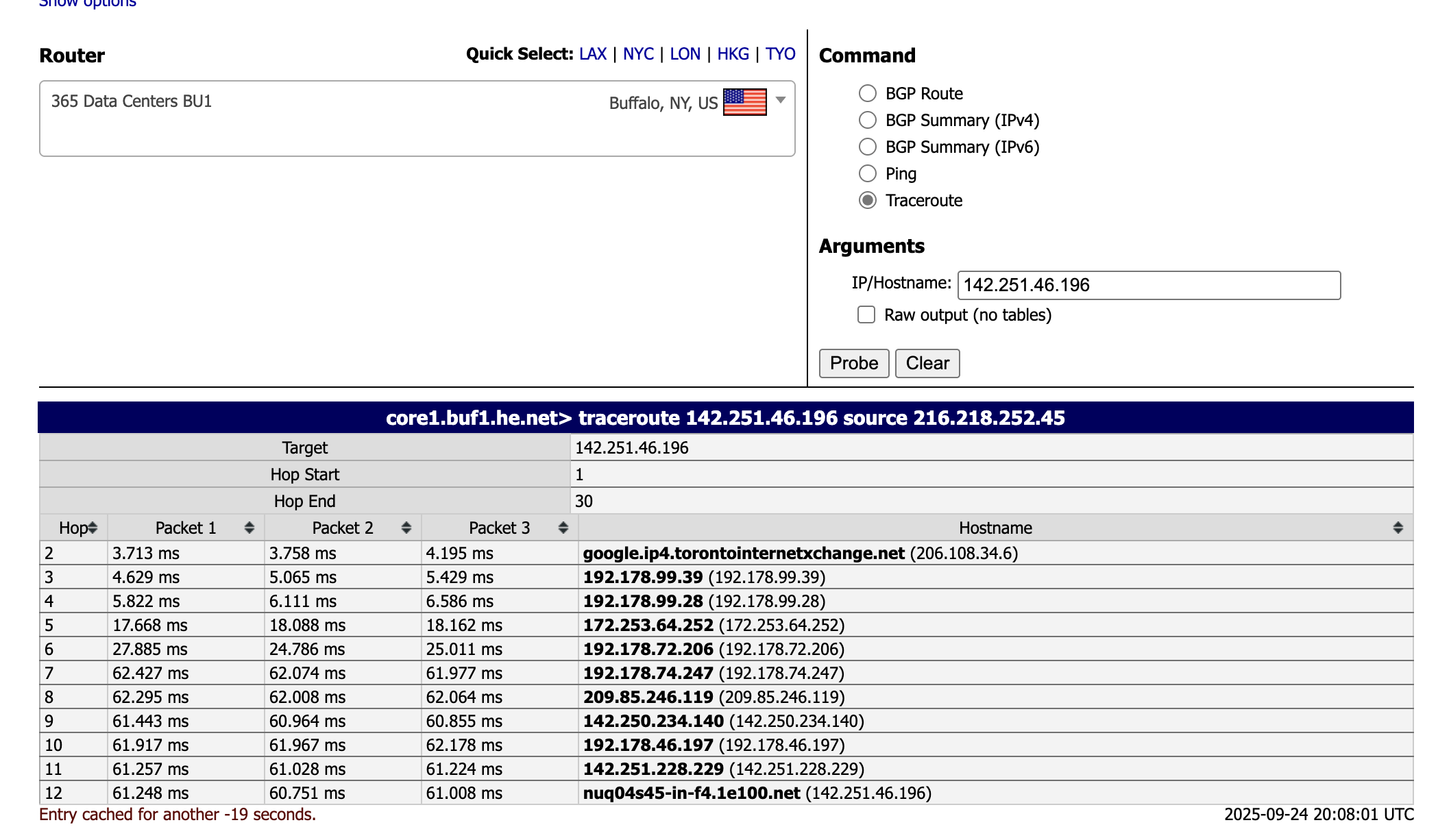
你执行的命令是:
traceroute 142.251.46.196 source 216.218.252.45含义如下:
字段 含义 目标 IP 142.251.46.196,Google 的某个服务器(AS15169)源 IP 216.218.252.45,属于 Hurricane Electric 的节点(位于纽约州 Buffalo 数据中心)使用方式 从 HE.net 网络探测访问 Google 某个服务器的路径(链路上的每一跳) 这是一条典型的从 HE 到 Google 的路由路径,你看到的是从 HE 的核心网络穿越到 Google 边缘 POP 的路径。下面我们一跳一跳分析:
Hop IP / Hostname 说明 2 206.108.34.6→google.ip4.torontointernetxchange.netGoogle 在加拿大 Toronto 的互联网交换点(IXP)边缘节点,Google 的入口路由器之一 3~6 192.178.*.*私有地址段,疑似 HE 或 IXP 内部核心路由器私网/IXP 内链路跳转 7 192.178.74.247→ Google 的内部结构(Transit)跨越边境,转入 Google 核心网络 8 209.85.246.119→ Google ASN(AS15169)网络入口你正式进入 Google 的全球骨干网络 9 142.250.234.140→ Google GGC POP(可能是边缘 CDN)延迟降低,离你更近的边缘服务器 10 192.178.46.197→ 回到 Google 私有网络,内网跳转11 142.251.228.229→ Google POP(1e100.net 系列)12 142.251.46.196→nuq04s45-in-f4.1e100.net✅目标服务器Google 的 Fremont (NUQ) 数据中心终点,访问成功 注意:
-
1e100.net是 Google 的自有基础设施域名(1e100 = 10¹⁰⁰,象征“Googol”),表示这是 Google 官方服务器。 -
torontointernetxchange.net是加拿大的一个 Internet Exchange Point(IXP)——互联网交换中心 → 多个运营商(如 HE 和 Google)在这里连接,用于流量交换(互联互通,省钱省时)。 -
为什么有那么多
192.178.*.*?这很可能是 Hurricane Electric 内部使用的 私网链路段,或者是 Google 和 HE 合作设定的 非公开传输网段;注意:虽然192.178.0.0/16在 RIR 分配中是公网段,但很多大公司会将其“私用”。
总结解读
项目 内容 起点 Hurricane Electric 的 Buffalo 数据中心 终点 Google Fremont 数据中心(142.251.46.196) 经过 Toronto IXP → Google 骨干网 → 多段 Google 内部网络 最终到达 成功,延迟 61ms,路径健康稳定 是否属于 AS15169 是,全程由 HE + Google 托管 实际用途 可以分析全球路由走向、是否绕路、Google CDN 就近节点等 -
-
Graph-based routing(如 PCE、SDN 中的图算法替代 BGP)
现代网络(尤其是运营商/数据中心)正使用图算法替代 BGP 的路径选择逻辑,主要两种方式:
-
PCE(Path Computation Element):
一种集中式图路径计算架构,网络中的每个节点将拓扑/链路/延迟/带宽等信息上传给“路径计算控制器”,由它来全局最优寻路。例如
- MPLS 网络中部署 Traffic Engineering(TE)
- SD-WAN 中做 SLA 路由(延迟、丢包、带宽)
-
SDN + Segment Routing
Software Defined Networking(软件定义网络)+ Segment Routing(路径标签转发)。
通过控制器维护一张网络图,控制器使用 Dijkstra、K-shortest path 等算法全局寻路,并将路径注入转发设备
-
-
BGP Hijack(BGP 劫持攻击)
BGP 劫持是指一个自治系统(AS)错误或恶意地宣告了它本不拥有的 IP 前缀,导致全球部分或全部流量被错误引导到它的网络。
假设:Google 拥有 IP 段
8.8.8.0/24,由 AS15169 宣告。黑客控制了 AS64500,向其邻居通告了:
8.8.8.0/24 via AS64500。这就导致邻居 AS 认为这是一条合法路径;若 AS Path 更短(比如 AS64500 是直连),就会覆盖原始路径;世界上部分流量会被吸引到 AS64500;黑客可以选择 丢弃、监听、修改、转发 这些流量。这就导致了:通信中断(DoS)、中间人监听(MitM)、钓鱼攻击(重定向到假网站)、国家级攻击(例如:2022 年俄罗斯疑似对乌克兰网站进行 BGP 劫持)
防御手段:RPKI(Resource Public Key Infrastructure)
-
IP 前缀拥有者向 RIR(如 APNIC、ARIN)注册其合法的“路由宣告”
-
AS 必须具备授权才能通告这些前缀
-
使用 ROA(Route Origin Authorization)检查路径合法性
-
-
BGP Flapping(路由震荡)
BGP Flapping 是指某个前缀的路由通告状态在短时间内频繁发生 “添加 → 删除 → 添加 → 删除” 的反复变化。
原因包括:链路不稳定(物理中断、MTU错配),运营商误配置(例如低优先级路由被错误启用),恶意模拟故障(DDoS 干扰 BGP稳定性)
危害:
- 会导致路由器频繁重计算路径 → CPU飙高
- 转发表不一致 → 丢包/环路
- 整体网络“收敛时间”变长
防御机制:Route Dampening(路由抑制)
- 给每个不稳定前缀“打分”
- 如果震荡频率过高,就临时“封禁”这个前缀一段时间
- 只有稳定足够时间后才能重新启用
-
BGP 与 MPLS 的结合(骨干 QoS)
MPLS(多协议标签交换)是一种将 “包的转发”从“IP地址查表”变成“查标签” 的机制,能显著提高 转发效率、支持 QoS、流量工程 TE。
BGP + MPLS 的核心用途:
模块 功能描述 BGP 宣告 VPN 路由 每个 VPN 客户的前缀通过 BGP+标签分发 MPLS 转发骨干流量 MPLS 作为快速通道替代传统 IP 查表转发 实现 L3 VPN 不同客户隔离前缀(如企业 A 与 B 的地址都可以是 10.0.0.0/8) 支持 Traffic Engineering 控制高带宽路径、避开拥塞 例如:中国电信骨干网,企业 MPLS VPN 专线(如银企互联),云平台实现多租户网络隔离(如阿里云、AWS)
-
中国教育网(CERNET)的特殊路径(非 BGP)
CERNET 全称:中国教育和科研计算机网(China Education and Research Network),是国内首批大规模 IPv6 试点网络,面向大学、研究所,不直接连入商业公网
特征 CERNET 商业公网 运营者 教育部直属组织/高校网络中心 中国电信、联通、移动等 ISP 路由协议 多采用 静态路由 或 私有协议(非BGP) 基于 BGP 全球互联 出口访问 CERNET → CERNET2 → CSTNET → 国际教育网络 BGP 出口路由,连接全球主干 IP 地址 大部分为教育部分配的专用段 公网分配(可被其他 AS 宣告) 连接特性 教育网内访问超快,访问外网需转商业链路 全局路由互通 CERNET 的“非 BGP 路由”机制解释
- 教育网核心路由是“手动配置”或“专用域协议(如OSPF/IS-IS)”
- 并不把大多数前缀宣告到 BGP,因此主干网络无法查询 CERNET 前缀的 BGP 路由
- CERNET2(第二代)部分节点接入了 IPv6 BGP 互联,正在逐步标准化
(四)公网 IP 回访
现在我们已经完全搞清楚了 IP 访问的 机制,但是有了一个新问题:
局域网设备没有公网 IP,那公网服务器怎么才能把包“准确送回”这个设备?
这一切靠的是 NAT(网络地址转换)技术 + 端口映射/连接追踪。
我们假设你家有一台路由器,其 WAN 口 IP 是一个公网 IP,例如:
家用路由器公网IP:203.0.113.5
局域网设备(比如笔记本):192.168.1.100
访问目标服务器:142.251.46.196(比如 Google)
实际上,家用路由器一般不会有 公网IP,一般是处于ISP 的子网(广播域)中,被分配一个局域网 IP,但是原理相同。
步骤一:路由器 SNAT
你的电脑本地IP 为192.168.1.100,使用端口 50123 向谷歌 142.251.46.196:443 发送了一个请求:
源IP: 192.168.1.100
源端口: 50123
目的IP: 142.251.46.196
目的端口: 443
路由器收到数据包后, 会进行 SNAT(源地址转换),把这个访问请求从自己的 62000 端口发出。
修改为:
源IP: 203.0.113.5 # 路由器的公网IP
源端口: 62000 # 随机选一个未占用端口
目的IP: 142.251.46.196
目的端口: 443
并在 NAT 表里记录:
| 公网源端口 | 内网设备 IP | 内网源端口 |
|---|---|---|
| 62000 | 192.168.1.100 | 50123 |
除此之外,NAT 表还会记录
- 协议类型(TCP/UDP)
- 最后活动时间(会自动过期)
步骤二:公网服务器回包
公网服务器收到请求后,会回应一个数据包:
源IP: 142.251.46.196
源端口: 443
目的IP: 203.0.113.5
目的端口: 62000
看起来是在给公网 IP 回包,但注意这个端口是 62000。
步骤三:路由器 DNAT
路由器收到这个回应包后,查 NAT 表,发现端口 62000 是某个内网设备发出去的请求。
于是进行 DNAT(目标地址转换),把数据包改成:
目标IP: 192.168.1.100
目标端口: 50123
并发给局域网中的那台笔记本。
简而言之,服务器不用知道你真实 IP,是因为路由器维护了完整的映射,在 TCP ��层上,你的公网 IP + 端口 就代表你的“身份”。外部世界只看见路由器,你在“路由器的代理之下”工作
这也是防火墙、QoS、NAT、端口转发等功能的核心组件。Linux 路由器内核模块 conntrack 就是做这个的。
公网服务器(比如运行 HTTPS 服务的)就不用进行 NAT 端口映射,只用 443 端口进行收发,只有局域网设备才需要 NAT。
(五)边界网关协议(BGP)
我们之前讲到,ISP 会给路由器分配一个 IP,其实这个 IP 可能是公网 IP 也可能是局域网 IP。
情况1:分配公网 IP
如果 ISP 拥有足够公网 IP(如企业专线):
路由器拨号后直接获得一个公网 IP
路由器可直接作为 Internet 边缘主机使用
此时访问的线路走的是 BGP 协议(由 ISP 这个 AS 管理)
情况2:分配局域网 IP
大多数家庭宽带使用 CGNAT(Carrier Grade NAT),也就是运营商级别的 NAT
路由器拨号后分到的是 ISP 的私有地址段,比如:
-
100.64.0.0/10�(专用于 CGNAT) -
10.0.0.0/8 -
``172.16.0.0/12` 等
路由器和 ISP 网关之间的通信也发生在局域网,实际公网通信通过 ISP 的 NAT 映射转发
100.64.0.0/10 的完整 IP 范围:100.64.0.0 ~ 100.127.255.255。这个 IP 段是专门为**大型 NAT 网络(CGNAT)**保留的。
(六)域名
现在我们已经完全搞清楚了使用 IP 进行访问的机制,但是当我们上网时,更多使用的其实不是 IP ,而是域名如 www.baidu.com 。这是怎么实现的?
事实上,在局域网内访问 百度时,首先要进行 DNS域名解析,获取这个 域名对应的 IP,然后再使用 IP 进行访问。
1. 什么是域名
我们常见的 URL 如 www.heihet09.com 都是 主机名+域名。一个域名下可以有多个主机名,如 notes.heihet09.com
-
主机名比如
www.,是服务器名(主机名),一般会根据网站的功能命名, -
域名比如
heihet09.com,是要花钱买的
要查询 URL 对应的IP ,可以使用命令 nslookup
nslookup mail.sina.com.cn
购买域名可以上 万网:
- 买的只是域名,不需要加上主机名
www - 在买好之后,可以设置把
www.xxxxx指定到某一台服务器IP。一旦生效,全球可用。
域名构成是树形结构
根 <-> 顶级域名 <-> 一级域名 <-> 二级域名 <-> …… <-> 五级域名
例子: www.baidu.com.
注意这里最后有个点不打浏览器是会自动加上的
域名从后往前读:. 代表根域名,com 是顶级域名,baidu 是它之下的一级域名,www 是 baidu 下的二级域名
我们需要在万网购买的是1级域名 baidu.com
2. DNS 服务
DNS 即 Domain Name Service 域名服务,为客户机提供域名解析服务。
监听端口: TCP53 、UDP53
DNS解析种类:
-
按查询方式分类:
-
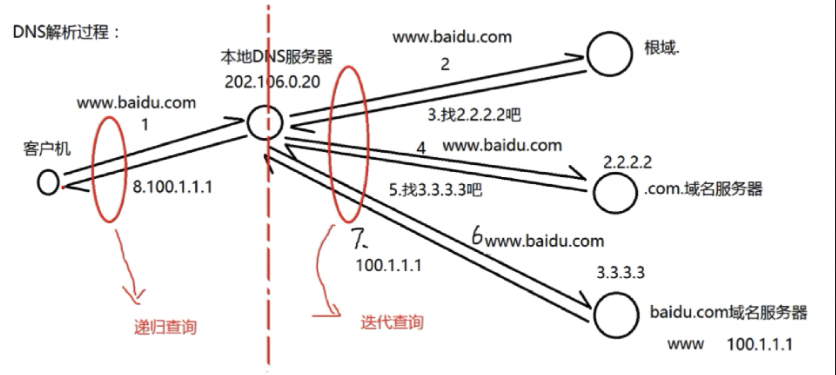
递归查询:客户机与本地DNS服务器之间,DNS转发器之间
-
迭代查询:本地DNS服务器与根等其他DNS服务器的解析过程
-
-
本地DNS服务器是指最近的、最先连上的DNS服务器
全世界的根服务器只有12个,大多在美国和日本
转发器:如果公司自己设置了一台DNS服务器,那么这会成为本地DNS服务器。若不想让这台服务器太累,可以使用转发器把查询根服务器等一系列任务转发给另外一台DNS服务器,从而减轻工作量。
-
-
按查询方式分类
- 正向解析:已知域名,解析IP
- 反向解析:已知IP,解析域名
DNS 有几种解析方法:
-
A记录:正向解析记录
-
CNAME记录:别名
-
PTR记录:反向解析记录
-
MX:邮件交换记录(专门用来做邮件服务器的)
-
NS:域名服务器解析(比如主要名称服务器和辅助名称服务器就是两台域名服务器)
到现在为止,我们已经有了两种让局域网设备不能访问真正的某公网服务器,而是把请求重定向到子网内另一台伪造服务器的办法。
- 在路由器上:创建和目标公网IP 相同IP 域的子网,把请求直接转发到该子网内
- 在 DNS 服务器上:直接把目标域名解析为一台本地服务器。
所以也可以根据这个原理搭建只能内部网络访问的网站,在内部客户机输入这个域名,直接由内部DNS服务器解析了,指向一个内部的服务器