第 4 课:数据加载(中)
在上一课中我们学习了数据加载的基本结构,这一章我们来补充学习 Dataset 加载过程中的一些其他操作
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import torchvision.transforms as transforms
from PIL import Image
import pandas as pd
import matplotlib.pyplot as plt
(一) transforms数据增强
在上一节的 Dataset 实例化过程中,我们用 transform 定义了图像的预处理过程,但是没有详细展开
比如
train_root_dir = "./data/covid-19-dataset-2/train"
transforms_func = transforms.Compose([
transforms.Resize((8, 8)), # 调整图像大小为 8x8
transforms.ToTensor(), # 转换为张量并归一化到 [0, 1]
])
# 实例化训练集
train_dataset = COVID19Dataset_2(root_dir=train_root_dir, transform=transforms_func)
torchvision.transforms 模块用于对图像数据进行预处理(调整大小、裁剪等)和数据增强(随机翻转、旋转等)。
可以是单个操作,也可以组合多个操作
为了方便后续可视化,我们预先定义几个可视化函数
# 将经过 transforms 预处理的图像数据反变换为原始图像形式
def transform_invert(img_, transform_train):
"""
将data 进行反transfrom操作
:param img_: tensor
:param transform_train: torchvision.transforms
:return: PIL image
"""
if 'Normalize' in str(transform_train):
# 筛选出 Normalize 变换
norm_transform = list(filter(lambda x: isinstance(x, transforms.Normalize), transform_train.transforms))
# 提取 mean 和 std 并转换为张量,与 img_ 的 dtype 和 device 保持一致
mean = torch.tensor(norm_transform[0].mean, dtype=img_.dtype, device=img_.device)
std = torch.tensor(norm_transform[0].std, dtype=img_.dtype, device=img_.device)
# 反归一化:将 img_ 乘以标准差并加上均值
img_.mul_(std[:, None, None]).add_(mean[:, None, None])
img_ = img_.transpose(0, 2).transpose(0, 1) # C*H*W 转换为 HWC 格式
# PIL.Image 需要输入 HWC 格式,而 PyTorch 张量默认是 CHW 格式。
# 如果包含 ToTensor操作 或像素值范围在 [0, 1],将张量转为 NumPy 数组并放大到 [0, 255]。
if 'ToTensor' in str(transform_train) or img_.max() < 1:
img_ = img_.detach().numpy() * 255
if img_.shape[2] == 3: # 如果通道数为 3,转为 RGB 图像。
img_ = Image.fromarray(img_.astype('uint8')).convert('RGB')
elif img_.shape[2] == 1: # 如果通道数为 1,去掉单通道维度,转为灰度图。
img_ = Image.fromarray(img_.astype('uint8').squeeze())
else:
raise Exception("Invalid img shape, expected 1 or 3 in axis 2, but got {}!".format(img_.shape[2]) )
return img_
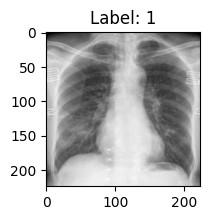
# 第一个样本可视化
def show_first_picture(train_data):
import matplotlib.pyplot as plt # 确保导入 Matplotlib
img, label = train_data[0]
print(f"第一个样本的图像大小: {img.shape}, 标签: {label}")
print(f"训练集样本数量: {len(train_data)}")
# 设置输出图像大小
plt.figure(figsize=(2, 2)) # 调整图像尺寸,单位是英寸
plt.imshow(img.squeeze(), cmap="gray")
plt.title(f"Label: {label}")
plt.show()
我们使用上一章中使用的第一个数据集
为了防止冗余,我把三个数据集都定义好了放在 COVID19Dataset 中
from Covid_DataSet import COVID19Dataset
root_dir = "./data/cov_19_demo" # 数据的根目录
img_dir = os.path.join(root_dir, "imgs")
path_txt_train = os.path.join(root_dir, "labels", "train.txt")
1. 转换为张量:transforms.ToTensor()
- 功能:将 PIL 图像或 NumPy 数组转换为 PyTorch 张量,同时将像素值从
[0, 255]归一化到[0.0, 1.0]。
transforms_func = transforms.Compose([
transforms.ToTensor()
])
train_data = COVID19Dataset(root_dir=img_dir, txt_path=path_txt_train, transform=transforms_func)
show_first_picture(train_data)
第一个样本的图像大小: torch.Size([1, 4095, 3342]), 标签: 1 训练集样本数量: 2
2. 调整大小:transforms.Resize()
- 功能:调整图像的尺寸。
- 参数:
size:目标大小,可以是单个整数(短边调整)或元组(H, W)。interpolation:插值方式(默认BILINEAR)。
transforms_func = transforms.Compose([
transforms.Resize((10, 10)), # 忽略原始长宽比,缩放大小为长宽都是 10px
transforms.ToTensor()
])
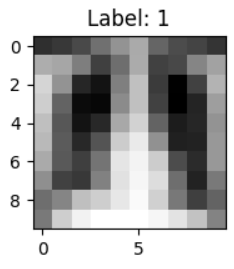
train_data = COVID19Dataset(root_dir=img_dir, txt_path=path_txt_train, transform=transforms_func)
show_first_picture(train_data)
第一个样本的图像大小: torch.Size([1, 10, 10]), 标签: 1 训练集样本数量: 2
思考:可不可以改成 transforms.Resize(5)?
会报错!因为 当输入 size 是单个整数时,resize会调整图像的 短边 长度为 size,同时保持原始图像的宽高比。
也就是图像会按比例缩放,短边被调整为 size,长边会根据原始宽高比计算得出。
而 当输入 size 是元组 (H, W) 时,强制将图像调整为指定的高度 H 和宽度 W,不保持宽高比。
此外注意:由于等比缩放之后的长边长度不一定是整数,因此会取整
当使用 transforms.Resize(5) 时,如果
- 输入图像 1 的原始大小为 (53, 10),调整后为 (26, 5)
- 输入图像 2 的原始大小为 (51, 10),调整后为 (25, 5)
由于形状不一致,抛出RuntimeError。
而输入 size 很小时(比如2),由于太小可能导致最后呈现的图片尺寸可能都一样
- 输入图像 1 的原始大小为 (53, 10),调整后为 (10, 2)
- 输入图像 2 的原始大小为 (51, 10),调整后为 (10, 2)
3. 中心裁剪:transforms.CenterCrop()
- 功能:从图像中心裁剪指定大小的区域。
- 参数:
size:目标大小,可以是单个整数或元组(H, W)。
transforms_func = transforms.Compose([
transforms.CenterCrop(100), # 从中心裁剪 100x100
transforms.ToTensor()
])
train_data = COVID19Dataset(root_dir=img_dir, txt_path=path_txt_train, transform=transforms_func)
show_first_picture(train_data)
第一个样本的图像大小: torch.Size([1, 100, 100]), 标签: 1 训练集样本数量: 2
4. 随机裁剪:transforms.RandomCrop()
- 功能:随机裁剪指定大小的区域,用于数据增强。
- 参数:
size:目标大小,可以是单个整数或元组(H, W)。padding:是否在裁剪前对图像边缘进行填充。
transforms_func = transforms.Compose([
transforms.RandomCrop((10, 10), padding=4), # 随机裁剪 10x10,并在边缘填充 4 像素
transforms.ToTensor()
])
train_data = COVID19Dataset(root_dir=img_dir, txt_path=path_txt_train, transform=transforms_func)
show_first_picture(train_data)
第一个样本的图像大小: torch.Size([1, 10, 10]), 标签: 1 训练集样本数量: 2
5. 随机水平翻转:transforms.RandomHorizontalFlip()
- 功能:以指定概率随机水平翻转图像。
- 参数:
p:翻转的概率(默认值为 0.5)。
transforms_func = transforms.Compose([
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor()
])
train_data = COVID19Dataset(root_dir=img_dir, txt_path=path_txt_train, transform=transforms_func)
show_first_picture(train_data)
第一个样本的图像大小: torch.Size([1, 4095, 3342]), 标签: 1 训练集样本数量: 2
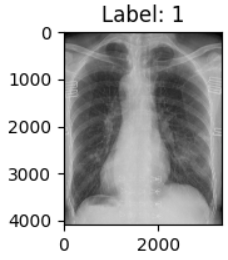
6. 随机垂直翻转:transforms.RandomVerticalFlip()
- 功能:以指定概率随机垂直翻转图像。
- 参数:
p:翻转的概率(默认值为 0.5)。
transforms_func = transforms.Compose([
transforms.RandomVerticalFlip(p=0.5),
transforms.ToTensor()
])
train_data = COVID19Dataset(root_dir=img_dir, txt_path=path_txt_train, transform=transforms_func)
show_first_picture(train_data)
第一个样本的图像大小: torch.Size([1, 4095, 3342]), 标签: 1 训练集样本数量: 2
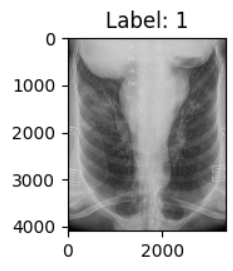
7. 随机旋转:transforms.RandomRotation()
- 功能:随机旋转图像。
- 参数:
degrees:旋转角度范围(例如(-30, 30))。
transforms_func = transforms.Compose([
transforms.RandomRotation(degrees=(-30, 30)), # 随机旋转 -30 到 30 度
transforms.ToTensor()
])
train_data = COVID19Dataset(root_dir=img_dir, txt_path=path_txt_train, transform=transforms_func)
show_first_picture(train_data)
第一个样本的图像大小: torch.Size([1, 4095, 3342]), 标签: 1 训练集样本数量: 2
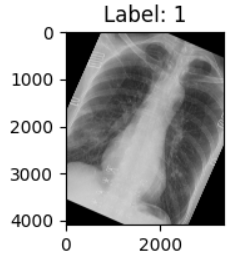
8. 颜色抖动:transforms.ColorJitter()
- 功能:随机改变图像的亮度、对比度、饱和度和色调。
- 参数:
brightness:亮度调整范围。contrast:对比度调整范围。saturation:饱和度调整范围。hue:色调调整范围。
transforms_func = transforms.Compose([
transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.1),
transforms.ToTensor()
])
train_data = COVID19Dataset(root_dir=img_dir, txt_path=path_txt_train, transform=transforms_func)
show_first_picture(train_data)
第一个样本的图像大小: torch.Size([1, 4095, 3342]), 标签: 1 训练集样本数量: 2
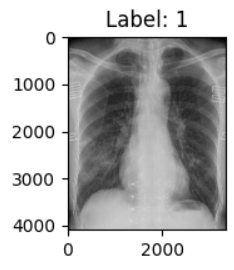
9. 归一化:transforms.Normalize()
-
功能:对张量进行归一化处理,将像素值标准化为指定的均值和标准差。
-
参数:
mean:每个通道的均值。std:每个通道的标准差。
-
注意:Normalize 只能作用于 Tensor 类型的数据,不能直接处理 PIL.Image。
因此必须要被放置在 transforms.ToTensor 之后!
transforms_func = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.5,), std=(0.5,)) # 单通道图像
# transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)), # RGB 图像
])
train_data = COVID19Dataset(root_dir=img_dir, txt_path=path_txt_train, transform=transforms_func)
show_first_picture(train_data)
第一个样本的图像大小: torch.Size([1, 4095, 3342]), 标签: 1 训练集样本数量: 2
10. 组合多个操作:transforms.Compose()
功能
transforms.Compose 用于将多个 transform 操作按顺序组合起来,形成一个流水线。
其原理是一开始采用transforms.Compose把变换的方法包装起来,放到dataset中;
在dataloader依次读数据时,调用dataset的getitem,每个sample读取时,会根据compose里的方法依次地对数据进行变换,以此完成在线数据增强。
而具体的transforms方法通常包装成一个Module类,具体实现会在各functional中。
transforms_func = transforms.Compose([
transforms.Resize((128, 128)), # 图像调整为 128x128。
transforms.RandomHorizontalFlip(), # 以 0.5 的概率翻转。
transforms.ToTensor(), # 将图像转换为 PyTorch 张量。
transforms.Normalize(mean=(0.5,), std=(0.5,)), # 将像素值标准化到均值为 0.5,标准差为 0.5。
])
train_data = COVID19Dataset(root_dir=img_dir, txt_path=path_txt_train, transform=transforms_func)
show_first_picture(train_data)
第一个样本的图像大小: torch.Size([1, 128, 128]), 标签: 1 训练集样本数量: 2
11. 自定义 Transform
除了 transforms 提供的常见方法,你还可以通过自定义 Transform 来实现特殊需求。
class AddGaussianNoise(object):
def __init__(self, mean=0.0, std=1.0):
self.mean = mean
self.std = std
def __call__(self, tensor):
noise = torch.randn(tensor.size()) * self.std + self.mean
return tensor + noise
# 使用自定义 transforms
transforms_func = transforms.Compose([
transforms.ToTensor(),
AddGaussianNoise(mean=0, std=0.1),
])
train_data = COVID19Dataset(root_dir=img_dir, txt_path=path_txt_train, transform=transforms_func)
show_first_picture(train_data)
第一个样本的图像大小: torch.Size([1, 4095, 3342]), 标签: 1 训练集样本数量: 2
12. FiveCrop & TenCrop
FiveCrop
- 功能:从图像的四个角和中心裁剪出固定大小的区域,返回 5 个裁剪结果。
- 参数:
size:裁剪区域的大小,可以是整数(正方形)或元组(H, W)。
TenCrop
- 功能:在
FiveCrop的基础上,返回水平翻转的裁剪区域,最终生成 10 个裁剪结果。 - 参数:
size:裁剪区域大小。
def show_all_crops(train_data):
import matplotlib.pyplot as plt # 确保导入 Matplotlib
img, label = train_data[0]
print(f"第一个样本的图像大小: {img.shape}, 标签: {label}")
print(f"训练集样本数量: {len(train_data)}")
# 创建子图
picture_nums=len(img)
fig, axes = plt.subplots(1, picture_nums, figsize=(15, 3))
for i in range(picture_nums):
axes[i].imshow(img[i].squeeze(0).numpy(), cmap="gray")
axes[i].set_title(f"Crop {i+1}")
axes[i].axis('off') # 关闭坐标轴
plt.show()
transforms_func = transforms.Compose([
transforms.FiveCrop(size=100), # 裁剪 100x100 的区域
transforms.Lambda(lambda crops: torch.stack([transforms.ToTensor()(crop) for crop in crops])) # 转为张量
])
train_data = COVID19Dataset(root_dir=img_dir, txt_path=path_txt_train, transform=transforms_func)
# 调用函数显示所有裁剪区域
show_all_crops(train_data)
第一个样本的图像大小: torch.Size([5, 1, 100, 100]), 标签: 1 训练集样本数量: 2

transforms_func = transforms.Compose([
transforms.TenCrop(size=(100, 100)), # 裁剪 100x100 的区域
transforms.Lambda(lambda crops: torch.stack([transforms.ToTensor()(crop) for crop in crops]))
])
train_data = COVID19Dataset(root_dir=img_dir, txt_path=path_txt_train, transform=transforms_func)
# 调用函数显示所有裁剪区域
show_all_crops(train_data)
第一个样本的图像大小: torch.Size([10, 1, 100, 100]), 标签: 1 训练集样本数量: 2

13. 随机选择操作:RandomChoice
- 功能:从多个 transforms 中随机选择一个进行应用。
- 参数:
transforms:一个 transform 列表。
random_operation = transforms.RandomChoice([
transforms.RandomHorizontalFlip(p=1.0),
transforms.RandomVerticalFlip(p=1.0),
transforms.RandomRotation(degrees=30)
])
transforms_func = transforms.Compose([
transforms.ToTensor(), # 裁剪 100x100 的区域
random_operation
])
train_data = COVID19Dataset(root_dir=img_dir, txt_path=path_txt_train, transform=transforms_func)
show_first_picture(train_data)
第一个样本的图像大小: torch.Size([1, 4095, 3342]), 标签: 1 训练集样本数量: 2
14. 随机排列操作顺序:RandomOrder
- 功能:随机改变多个 transforms 的应用顺序。
- 参数:
transforms:一个 transform 列表。
random_operation = transforms.RandomOrder([
transforms.ColorJitter(brightness=0.5),
transforms.RandomRotation(degrees=30),
transforms.RandomHorizontalFlip()
])
transforms_func = transforms.Compose([
transforms.ToTensor(), # 裁剪 100x100 的区域
random_operation
])
train_data = COVID19Dataset(root_dir=img_dir, txt_path=path_txt_train, transform=transforms_func)
show_first_picture(train_data)
第一个样本的图像大小: torch.Size([1, 4095, 3342]), 标签: 1 训练集样本数量: 2
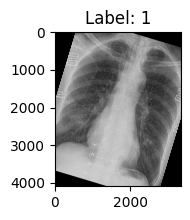
15. 随机应用一个或多个操作:RandomApply
- 功能:以一定概率随机应用一个或多个 transforms。
- 参数:
transforms:一个 transform 列表。p:应用的概率。
random_operation = transforms.RandomApply([
transforms.ColorJitter(brightness=0.5),
transforms.RandomRotation(degrees=30)
], p=0.5)
transforms_func = transforms.Compose([
transforms.ToTensor(), # 裁剪 100x100 的区域
random_operation
])
train_data = COVID19Dataset(root_dir=img_dir, txt_path=path_txt_train, transform=transforms_func)
show_first_picture(train_data)
第一个样本的图像大小: torch.Size([1, 4095, 3342]), 标签: 1 训练集样本数量: 2
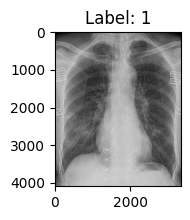
16. 自动数据增强:AutoAugment
- 功能:预定义的自动数据增强策略,支持以下几种策略:
ImageNet:针对 ImageNet 数据集。CIFAR10:针对 CIFAR-10 数据集。SVHN:针对 SVHN 数据集
def show_first_picture(train_data):
img, label = train_data[0]
# 将 PIL.Image 转换为 Tensor(如果没有转换)
if not isinstance(img, torch.Tensor):
img = transforms.ToTensor()(img)
# 打印图像的大小
print(f"第一个样本的图像大小: {img.shape}, 标签: {label}")
print(f"训练集样本数量: {len(train_data)}")
# 设置输出图像大小
plt.figure(figsize=(2, 2)) # 调整图像尺寸,单位是英寸
plt.imshow(img.squeeze(0).numpy(), cmap="gray") # 使用灰度图显示
plt.title(f"Label: {label}")
plt.show()
policy = transforms.AutoAugmentPolicy.CIFAR10
# policy = transforms.AutoAugmentPolicy.IMAGENET
# policy = transforms.AutoAugmentPolicy.SVHN
transforms_func = transforms.Compose([
transforms.AutoAugment(policy),
transforms.ToTensor(),
transforms.Normalize([0.4], [0.2]) # 由于本dataset是灰度图,仅1个通道,就不在展示3通道的使用。
])
transforms_func = transforms.AutoAugment(policy)
train_data = COVID19Dataset(root_dir=img_dir, txt_path=path_txt_train, transform=transforms_func)
show_first_picture(train_data)
第一个样本的图像大小: torch.Size([1, 4095, 3342]), 标签: 1 训练集样本数量: 2
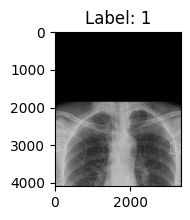
17. 轻量数据增强: TrivialAugmentWide
- 功能:实现随机数据增强,每次对图像应用随机的轻量增强操作,适合简单模型或资源有限的训练。
transforms_func = transforms.Compose([
transforms.Resize((224, 224)),
transforms.TrivialAugmentWide(),
transforms.ToTensor(),
transforms.Normalize([0.4], [0.2]) # 由于本dataset是灰度图,仅1个通道,就不在展示3通道的使用。
])
train_data = COVID19Dataset(root_dir=img_dir, txt_path=path_txt_train, transform=transforms_func)
show_first_picture(train_data)
第一个样本的图像大小: torch.Size([1, 224, 224]), 标签: 1 训练集样本数量: 2
18. Lambda
- 功能:允许定义自定义的 transform 函数。
- 参数:
lambda函数:自定义的变换逻辑。
transform = transforms.Lambda(lambda x: x * 255 if x.max() <= 1 else x)
(二)数据集的拼接
数据的来源往往是多源的,可能是多个中心的或多个时间段,很难将可用数据统一到一个数据形式。
通常有两种做法:
- 整理所有数据,变为同一格式,然后用一个Dataset即可读取。
- 为每批数据编写一个Dataset,然后使用
torch.utils.data.ConcatDataset类将他们拼接起来
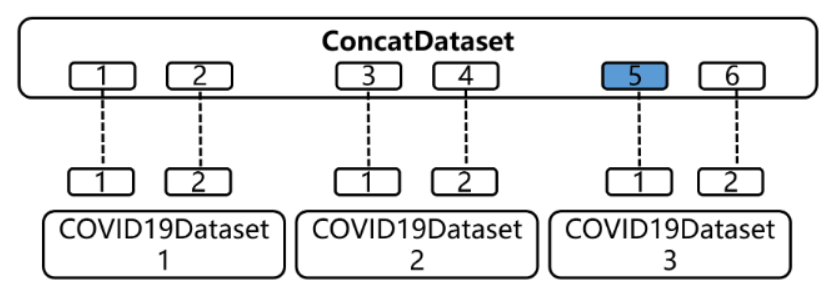
在(上)中我们分别实现了三种数据集 COVID19Dataset、COVID19Dataset2、COVID19Dataset3,
可以用concat来把 3个数据集拼接得到总的数据集,数据量为2+2+2=6
ConcatDataset 其实还是一个dataset类,它内部还是有len和getitem。
其 __getitem___函数 的工作原理如下:
- 假设
dataloader想要第5个样本,传入index=4, getitem计算出 第五个样本 在 第三个数据集的第1个位置。- 通过
self.datasets[datasetidx][sampleidx]来获取数据。
因此,其实实际上 内部 仍旧调用各个 子dataset 的__getitem
from torch.utils.data import ConcatDataset, DataLoader
from torchvision import transforms
from Covid_DataSet import COVID19Dataset,COVID19Dataset_2,COVID19Dataset_3
# 数据预处理操作
transforms_func = transforms.Compose([
transforms.Resize((8, 8)), # 调整图像大小为 8x8
transforms.ToTensor(), # 转换为张量并归一化到 [0, 1]
transforms.Normalize([0.4], [0.2]) # 归一化(仅适用于单通道图像)
])
# 实例化训练集
train_data1 = COVID19Dataset(root_dir=img_dir, txt_path=path_txt_train, transform=transforms_func)
train_data2 = COVID19Dataset_2(root_dir="./data/covid-19-dataset-2/train", transform=transforms_func)
train_data3 = COVID19Dataset_3(root_dir="./data/covid-19-dataset-3/imgs", path_csv="./data/covid-19-dataset-3/dataset-meta-data.csv", mode="train", transform=transforms_func)
# 合并训练集
train_data_combined = ConcatDataset([train_data1, train_data2, train_data3])
# 使用 DataLoader 加载合并后的训练集
train_loader = DataLoader(train_data_combined, batch_size=64, shuffle=True)
# 打印第一个批次的数据
for images, labels in train_loader:
print(f"图像大小: {images.shape}, 标签: {labels}")
break
当前扫描路径:./data/covid-19-dataset-2/train,该路径下子文件夹:['no-finding', 'covid-19'],子文件[] 当前扫描路径:./data/covid-19-dataset-2/train/no-finding,该路径下子文件夹:[],子文件['00001215_001.png'] 当前扫描路径:./data/covid-19-dataset-2/train/covid-19,该路径下子文件夹:[],子文件['ryct.2020200028.fig1a.jpeg'] 图像大小: torch.Size([6, 1, 8, 8]), 标签: tensor([0, 1, 0, 1, 0, 1])
此外:
如果获取了大量的COVID-19数据,肯定是多源的,如何把他们整理起来供模型训练呢?
可以将采集到的数据统一整理,并生成metadata(元信息)。
基于现成的Dataset,我们可通过拼接的方法将所有数据拼接成一个大的dataset进行使用。
整理好的数据在这里:https://github.com/ieee8023/covid-chestxray-dataset/blob/master/metadata.csv
(三)从数据集生成子数据集
torch.utils.data.Subset 用于从一个现有的 Dataset 中抽取一个子集(Subset),且不修改原始 Dataset
这在数据集较大或只需要部分数据进行训练或测试时非常有用。
也可以 将数据集划分为训练集、验证集和测试集。
和ConcatDataset一样,Subset 是对原始 Dataset 的包装,访问子集时:
__len__返回子集大小。__getitem__按索引从原始数据集中提取样本。
Subset 需要两个参数:
dataset:原始数据集,必须是一个 PyTorchDataset对象indices:一个索引列表,用于指定需要抽取的样本。
from torch.utils.data import Dataset, DataLoader, Subset
from torchvision import datasets, transforms
# 定义数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 加载完整的 MNIST 数据集
dataset = datasets.MNIST(root="./data", train=True, download=True, transform=transform)
# 创建一个子集
indices = list(range(1000)) # 选择前 1000 个样本
subset = Subset(dataset, indices)
# 使用 DataLoader 加载子集
dataloader = DataLoader(subset, batch_size=64, shuffle=True)
# 打印一个批次数据
for images, labels in dataloader:
print(f"图像大小: {images.shape}")
print(f"标签: {labels}")
break
图像大小: torch.Size([64, 1, 28, 28]) 标签: tensor([7, 0, 4, 4, 0, 1, 8, 9, 5, 5, 4, 7, 9, 4, 5, 5, 8, 9, 3, 7, 2, 4, 3, 8, 0, 0, 0, 8, 7, 9, 9, 4, 1, 0, 5, 1, 5, 4, 5, 8, 6, 8, 9, 5, 5, 6, 8, 8, 1, 1, 7, 5, 9, 0, 4, 6, 0, 3, 7, 7, 1, 3, 8, 2])
使用 Subset 和 torch.utils.data.random_split,可以将一个数据集划分为训练集和验证集。
from torch.utils.data import random_split
# 数据集总长度
dataset_size = len(dataset)
# 划分比例
train_size = int(0.8 * dataset_size) # 80% 用于训练
valid_size = dataset_size - train_size # 剩下的用于验证
# 随机划分数据集
train_subset, valid_subset = random_split(dataset, [train_size, valid_size])
# 分别加载训练集和验证集
train_loader = DataLoader(train_subset, batch_size=64, shuffle=True)
valid_loader = DataLoader(valid_subset, batch_size=64, shuffle=False)
如果有特定的样本索引可以直接使用 Subset:
# 指定索引
indices = [0, 10, 20, 30] # 选择第 0, 10, 20, 30 个样本
specific_subset = Subset(dataset, indices)
# 使用 DataLoader 加载
specific_loader = DataLoader(specific_subset, batch_size=2, shuffle=False)
# 打印数据
for images, labels in specific_loader:
print(f"图像大小: {images.shape}")
print(f"标签: {labels}")
break
如果需要根据条件选择样本,例如筛选特定类别,可以通过构建索引实现:
# 筛选标签为 0 和 1 的样本
indices = [i for i, (img, label) in enumerate(dataset) if label in [0, 1]]
# 创建子集
filtered_subset = Subset(dataset, indices)
# 使用 DataLoader 加载
filtered_loader = DataLoader(filtered_subset, batch_size=64, shuffle=True)
# 打印数据
for images, labels in filtered_loader:
print(f"图像大小: {images.shape}")
print(f"标签: {labels}")
break
高级用法:结合 WeightedRandomSampler,可以在子集上实现基于权重的采样
from torch.utils.data import WeightedRandomSampler
# 子集索引
indices = list(range(1000))
subset = Subset(dataset, indices)
# 定义采样权重
weights = [0.1] * 500 + [0.9] * 500 # 前 500 个权重小,后 500 个权重大
sampler = WeightedRandomSampler(weights, num_samples=100, replacement=True)
# DataLoader
loader = DataLoader(subset, batch_size=10, sampler=sampler)
for images, labels in loader:
print(f"图像大小: {images.shape}")
print(f"标签: {labels}")
break