第 9 课:残差网络
(ResNetS)
残差网络的结构
非常非常深的神经网络是很难训练的,因为存在梯度消失和梯度爆炸问题。
而跳跃连接( Skip connection),它可以从某一层网络层获取激活,然后迅速反馈给另外一层,甚至是神经网络的更深层。
我们可以利用 跳跃连接 构建残差网络 ResNets, 有时深度能够超过 100层
ResNets 网络是由残差块(Residual block)构成的, 什么是残差块呢?
普通的神经网络的计算步骤是这样的
而残差块会修改如下:
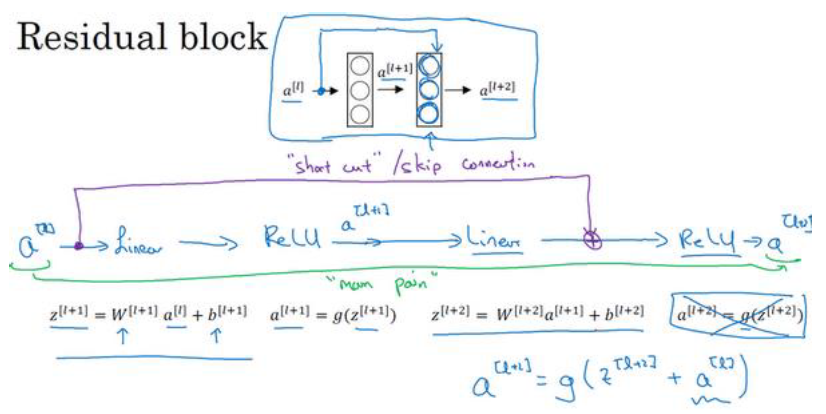
也就是把最后一步改成了
也就是把 直接拷贝到神经网络的深层
上面的这一整个叫一个残差块,这里选择跳跃连接了1层,有时可以跳跃连接好几层
一个 ResNet 网络就是很多这样的残差块堆积在一起,可以形成很深的神经网络
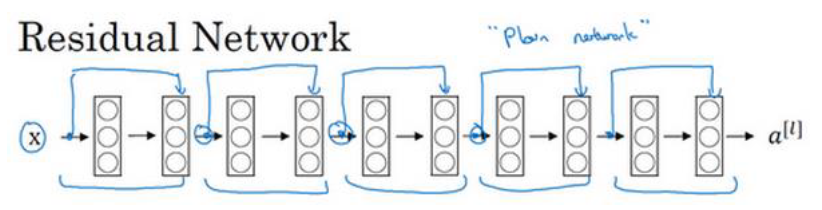
把普通网络 (Plain Network) 变成 ResNet 的方法是加上所有跳跃连接,比如每两层增加一个捷径,构成一个残差块。
如图所示 ,5个残差块连接在一起构成一个残差网络。
残差网络相比普通网络的性能差别如下:
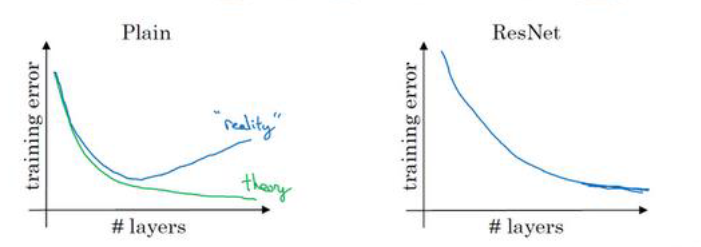
残差网络的优点
残差网络使得网络在增加深度的同时能有效避免梯度消失或爆炸的问题,保持网络训练的稳定性,从而实现更深层次的网络构建而不会导致性能下降。
- 跳跃连接:即使更深层的网络层没有学到有效的特征,网络仍然可以利用之前层的特征学习。
- 梯度流:在反向传播时,跳跃连接提供了一条没有任何非线性变换的直接路径,这意味着梯度可以更直接地流回输入层,避免了在深层网络中常见的梯度消失问题。因此,即使网络非常深,梯度也能有效地传播
代码实现
一个 简易版 ResNet18 结构,也是官方 torchvision.models.resnet 的简化版
- ResNet = 很多个 残差块(Residual Block) 堆叠
- 每个残差块有一个“跳跃连接(Skip Connection)”
- 解决深层网络的梯度消失问题
首先要定义一个残差块
import torch
import torch.nn as nn
import torch.nn.functional as F
# 定义一个残差块
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(ResidualBlock, self).__init__()
# 卷积层1
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
# 卷积层2
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
# 下采样层 (shortcut 使用)
self.downsample = downsample
def forward(self, x):
identity = x # shortcut 分支
out = self.conv1(x)
out = self.bn1(out)
out = F.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity # 残差连接
out = F.relu(out)
return out
下采样层
downsample
self.downsample = downsample
如果 in_channels != out_channels 或 stride != 1,就用 downsample 把 shortcut 变形
如果 in_channels == out_channels 且 stride == 1,downsample=None,不用改
对于一个正常残差块,结构如下
输入:x → conv1 → conv2 → out
输入:identity(原始 x) → 跳跃加到 out
最终: out = conv_out + identity关键是:out 和 identity 要“能加在一起” → 形状必须一致
如果 stride=1,通道数不变 → 可以直接相加,不需要
downsample如果 stride=2(即降采样),或者通道数变了 → 就不能直接相加,这时候需要
downsample把 identity 变换成和 out 一样的形状不需要
downsample的情况ResidualBlock(64, 64, stride=1) # 输入: x → (batch, 64, H, W) # 输出: out → (batch, 64, H, W) # identity: (batch, 64, H, W) # 直接 out += identity 就行需要
downsample的情况ResidualBlock(64, 128, stride=2) # 输入: x → (batch, 64, H, W) # 输出: out → (batch, 128, H/2, W/2) # identity: (batch, 64, H, W) # 形状不一样,identity 需要 downsample 变成 (batch, 128, H/2, W/2) # 才能 out += identity所以
downsample是什么?self.downsample = nn.Sequential( nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False), nn.BatchNorm2d(out_channels) )
downsample的作用是 调整 identity 的形状,让它匹配主分支 out:
- 改 stride
- 改通道数
定义 ResNet 网络(例如 ResNet18)
| 层次 | 组成 |
|---|---|
| Conv1 | 7x7 conv, stride 2 + BN + ReLU + MaxPool |
| Layer1 | 2 个 残差块,out_channels = 64 |
| Layer2 | 2 个 残差块,out_channels = 128 |
| Layer3 | 2 个 残差块,out_channels = 256 |
| Layer4 | 2 个 残差块,out_channels = 512 |
| AvgPool | Adaptive avg pool (1x1) |
| FC | 512 → num_classes |
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=10): # 10 类分类
super(ResNet, self).__init__()
self.in_channels = 64
# 初始层 conv + bn + relu + maxpool
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False) # 3 通道输入
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 残差块堆叠
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
# 最终分类层
self.avgpool = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(512, num_classes)
def _make_layer(self, block, out_channels, blocks, stride=1):
downsample = None
if stride != 1 or self.in_channels != out_channels:
downsample = nn.Sequential(
nn.Conv2d(self.in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels)
)
layers = []
layers.append(block(self.in_channels, out_channels, stride, downsample))
self.in_channels = out_channels
for _ in range(1, blocks):
layers.append(block(out_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x) # (batch, 64, H/2, W/2)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x) # (batch, 64, H/4, W/4)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x) # (batch, 512, 1, 1)
x = torch.flatten(x, 1) # (batch, 512)
x = self.fc(x) # (batch, num_classes)
return x
构造 ResNet18
def ResNet18(num_classes=10):
return ResNet(ResidualBlock, [2, 2, 2, 2], num_classes)
使用示例
model = ResNet18(num_classes=10).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()