第 7 课:如何优化机器学习项目
在这一部分中,技术性的东西会比较少,更多的是一些项目优化的经验和策略
(一)正交化
(orthogonalization)
搭建建立机器学习系统的挑战之一是,有那么多的超参数可以调, 你可以尝试和改变的东西太多太多了。
而所谓 正交化 , 就是每一个调整的内容只影响某一个性质,否则调整一个内容但是影响了很多性质,会让调试变得困难。
我们在前面说过样本要分为训练集,开发集和测试集。
我们首先要保证在训练集上效果不错,其次是开发集,然后是测试集,最后是实际应用中。
在不同的阶段出现问题对应的解决办法是不一样的。

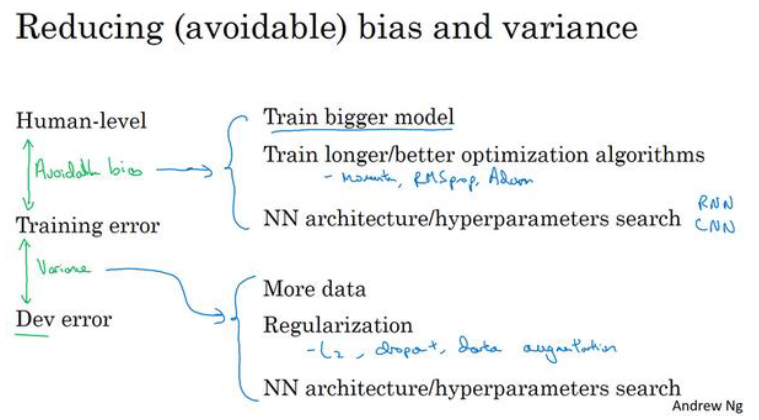
- 在训练集上表现不好: 使用更大的网络,使用更好的算法(比如Adam)
- 在训练集上表现好,但是在开发集上表现不好: 正则化,增大训练集
- 在开发集上表现好,但是在测试集上表现不好: 更大的开发集,
- 在测试集上表现好,但是在实际��中表现不好: 改变开发集或者成本函数
(二)单一数字评估指标
如果你有一个单实数评估指标,你的进展会快得多
但是有些时候并没有那么容易确定 单实数评估指标,请看下例
示例一
查准率(Precision)是在你的分类器标记为猫的例子中,有多少真的是猫。
查全率(recall)是对于所有真猫的图片,你的分类器正确识别出了多少百分比
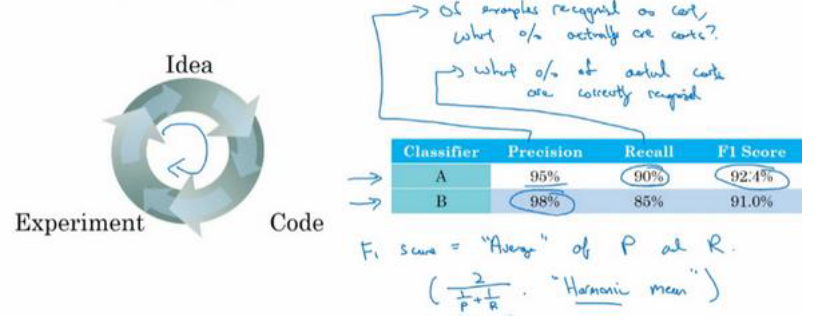
那么这两个指标该选哪一个作为评估指标呢?
一般建议取调和平均数 �进行比较:
越大,代表准确率越高
示例二
看下面这个例子,准确率和运算时间之间,应该如何权衡呢?

事实上,比如在1000ms内用户感觉不出区别,所以只要满足运算时间小于1000ms即可,只需要在剩下的里面比较准确率,所以选B
更一般地说,如果要考虑N个指标,有时候可以只选择其中一个作为评判标准,剩下的只要满足某个要求就可以了
你已经学过如何设置开发集和评估指标,就像是把目标定在某个位置,让你的团队瞄准。
但有时候在项目进行途中,你可能意识到,目标的位置放错了。这种情况下��,你应该移动你的目标。
如果你对旧的错误率指标不满意,就不要一直沿用你不满意的错误率指标,而应该尝试定义一个新的指标,能够更加符合你的偏好,定义出实际更适合的算法。
(三)训练 /开发 /测试集划分
机器学习中的工作流程是,你尝试很多思路,用训练集训练不同的模型,然后使用开发集来评估不同的思路,
然后选择一个,然后不断迭代去改善开发集的性能,直到最后你可以得到一个令你满意的成本,然后你再用测试集去评估。
同时,开发集和测试集需要来自相同的分布,不可以开发集的图片都是北半球,测试集的图片里都是南半球的
关于大小的划分,我们之前说过是 7:3 或者 6:2:2 , 但是如果数据体量上到百万级别, 98:1:1 会更合理。毕竟测试集只要反映全面性能就可以了。
(四)人的表现
Human-level performance
在不断地提升准确率的同时,AI的能力会超过人类
但是如下图所示,在能力超过人类后,进步速度会变慢,并且最后无论如何也不能超过一个所谓的“贝叶斯最优错误率( Bayes optimal error)”
贝叶斯最优错误率一般认为是理论上可能达到的最优错误率
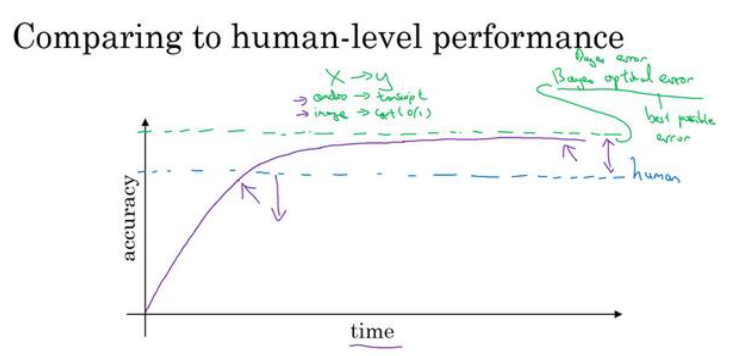
贝叶斯错误率或者对贝叶斯错误率的估计 和 训练错误率 之间的差值称为 可避免偏差,
理论上是不可能超过贝叶斯错误率的,除非过拟合
注意: 人类水平 是指人类可以达到的最高水平 而不是平均水平! 而贝叶斯最优错误率必须要比人类水平 高一点或很多!
(五)迁移学习
也就是在别人训练好的模型和参数上继续训练
举个例子,假如说你要建立一个猫咪检测器,用来检测你自己的宠物猫。
假如你的两只猫叫 Tigger和Misty,所以要做一个三分类问题,图片里是 Tigger还是 Misty,或者都不是,(忽略两只猫同时出现在一张图片里的情况)。但是现在你可能没有Tigger或者 Misty的大量的图片,所以你的训练集会很小,你该怎么办呢?
-
从网上下载一些神经网络开源的实现,不仅把代码下载下来,也把权重下载下来。
举个例子, 假设这个网络使用ImageNet数据集进行训练,那么这个网络最后的 Softmax层 会进行1000分类。
-
去掉这个 Softmax 层,创建你自己的 Softmax单元,用来输出 Tigger、 Misty和neither三个类别。
就网络而言,最好冻结网络中所有层的参数,只需要训练和你的 Softmax层有关的参数。
上面说的是 手里有的数据集很小 的情况,如果你有一个更大的标定 的数据集(有大量的 Tigger和 Misty的照片),
你应该 冻结�更少的层,然后训练后面的层
如果你有越来越多的数据,你需要冻结的层数越少,你能够训练的层数就越多
极端情况下 ,你可以用下载的权重只作为初始化,用它们来代替随机初始化,接着你可以用梯度下降训练,更新网络所有层的所有权重。
代码实现
总结一句话:迁移学习 = 用别人训练好的网络 + 自己的任务继续训练 分两种情况:
- 数据量小 → 只训练最后几层(冻结大部分层)
- 数据量大 → 也可以 fine-tune 更多层甚至整个网络
代码示例(以 ResNet18 为例)
import torch
import torch.nn as nn
import torchvision.models as models
# 下载预训练模型(ImageNet 权重)
model = models.resnet18(pretrained=True) # 下载并加载 ResNet18 网络,默认是 1000 分类
# 冻结所有层(不训练)
for param in model.parameters(): # 遍历模型中所有参数(即每一层的权重和偏置)
param.requires_grad = False # 这些层不会更新参数,用途:特征提取
# 替换最后的 fc 层(3 分类:Tigger, Misty, neither)
num_features = model.fc.in_features # ResNet18 最后是一个全连接层,取得原来的 fc 层输入维度(通常是 512)
model.fc = nn.Linear(num_features, 3) # 新 fc 层定义为 nn.Linear(512, 3),需要训练
# 只训练新的 fc 层
optimizer = torch.optim.Adam(model.fc.parameters(), lr=0.001) # 优化器为 Adam,只优化 model.fc 这一层参数
criterion = nn.CrossEntropyLoss() # 定义损失函数为 CrossEntropyLoss(适合多分类 Softmax 输出)
训练循环(示例)
for epoch in range(num_epochs):
model.train()
for images, labels in train_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
如果数据量比较大 → 可以只冻结前几层
# 假设解冻 resnet.layer4 及其后的参数
for name, param in model.named_parameters():
if "layer4" in name or "fc" in name:
param.requires_grad = True
else:
param.requires_grad = False
然后 optimizer 改为:
optimizer = torch.optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=0.0001)