第 11 课:目标定位
(一)图像分类和定位算法
我们之前学习过图像分类,但是如何实现图像中的目标定位呢?
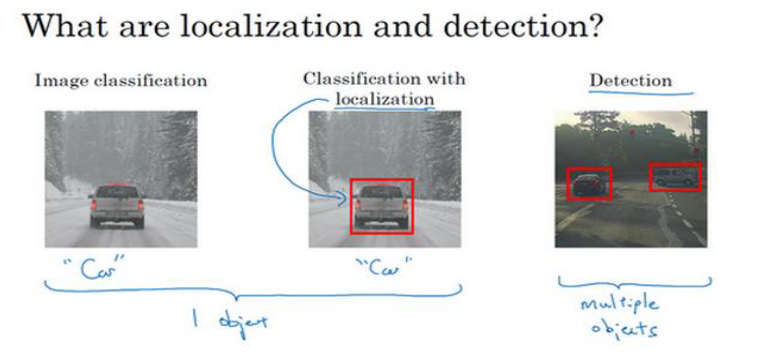
在之前的softmax回归中,假设我们要识别3 种目标,会输出一个 4 * 1 的向量,来表示每种目标的概率。
想要同时输出每种目标的位置,我们可以给每一个元素加上4个数字(变成一个数组), 分别是
我们约定图片左上角的坐标为(0,0),右下角标记为(1,1)。方框的中心点表示为 (𝑏𝑥,𝑏𝑦),边界框的高度为 𝑏ℎ,宽度为 𝑏𝑤。
比如𝑏𝑥的值是 0.5,表示汽车位于图片水平方向的中间位置; 𝑏𝑦大约是 0.7,表示汽车位于距离图片底部 3/10的位置;
𝑏ℎ约为 0.3,表示红色方框的高度是图片高度的 0.3倍; 𝑏𝑤约为 0.4,表示红色方框的宽度是图片宽度 的 0.4倍。
所以最后的输出标签 y 应该如下:
其中表示图中有目标,表示图中没有有目标,
时, 中只有一个为1,其他都为0,表示是哪一种目标
时, 其他参数毫无意义
该神经网络的损失函数为:
时
时 ,
使用神经网络是如何进行目标定位的?
在目标定位任务中,可以用一个已经训练好的分类网络(如VGG、ResNet等),��并修改最后的全连接层,使其输出中包含边界框的四个参数。
也就是说,调整最后全连接层的输出即可,不需要做出额外的操作,因为神经网络自己会去学习怎么定位。
如何衡量算法准确性:
我们使用 交并比函数 来评价对象检测算法

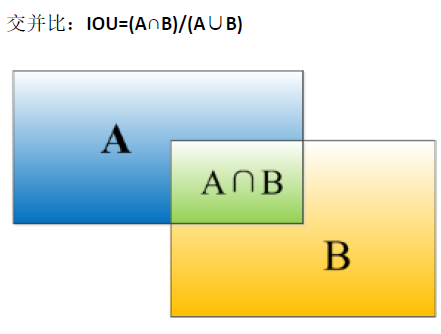
完美重叠时,IoU为1
IoU ≥ 0.5 时 认为检测正确
(二)特征点识别
上面我们采用的定位点是车的中心点,但是有时我们可以采用一些其他的特征点来定位,
比如在人脸识别算法中我们想知道眼角的具体位置,我们可以使用特征点
除了眼角,我们还可以得到更多的特征点输出,像下图中的特征点都是眼睛的特征点,根据这些输出来判断眼睛的形状,是睁眼还是眯眼

假设脸部有 64个特征点,有些点甚至可以帮助你定义脸部轮廓或下颌轮廓。此时我们就有了
再加上一个1或0表示是否有人脸,我们得到了一个含有129个输出单元的特征 l
此时我们没有用到宽和高参数,而是用到了很多的特征点来实现定位
为了构建这样的网络,你需要准备一个标签训练集,也就是图片 𝑥和标签 𝑦的集合,这些点都是人为辛苦标注的。
注意: 每个特��征点在所有图中表示的含义必须一致,比如特征点 1 始终是右眼的外眼角,特征点 2 始终是右眼的内眼角
(三)滑动窗口目标检测算法
假如你想构建一个汽车检测算法,首先要创建一个标签训练集。训练时可以剪切图片,使整张图片几乎都被汽车占据。
使用这些训练集训练出的神经网络,可以用于识别是否有汽车,也就是输出0或1即可
然后在一张图片中滑动一个特定大小的窗口,把这个小窗口内的东西输入神经网络 进行预测。
每次输入给卷积网络的只有窗口内的区域,依次重复操作,直到这个窗口滑过图像的每一个角落。

窗口的大小和移动的步幅都是可以调整的
然而因为卷积网络要一个个地处理每个小方块,所以如果你选用的步幅很大,粗糙间隔尺寸可能会影响性能。
如果采用小粒度或小步幅,传递给卷积网络的小窗口会特别多,计算成本很高
为了解决计算成本的问题,我们将使用 滑动窗口的卷积实现(Convolutional implementation of sliding windows)
为了构建滑动窗口的卷积应用,首先要知道如何把神经网络的全连接层转化成卷积层。
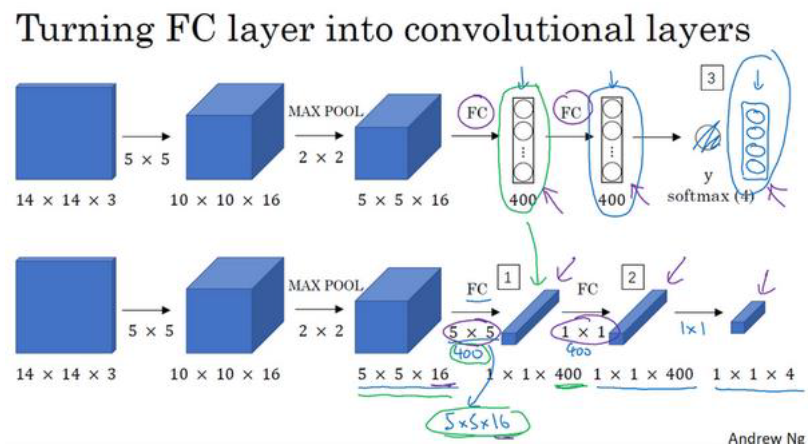
注意:
- 这里输出y有 4个数字,它们分别对应行人、汽车、摩托车和背景出现的概率。
- 这里的前几层是一样的,
对于第一个全连接层,替换为使用 5 * 5 * 16 的400个过滤器进行卷积操作,输出维度是 1×1×400
对于第二个全连接层,替换为使用 1 * 1 * 400 的400个过滤器进行卷积操作,输出维度是 1×1×400
最后的softmax层替换为使用 1 * 1 * 400 的 4个过滤器进行卷积操作,最终得到这个 1×1×4的输出层
掌握了卷积知识,我们再看看如何通过卷积实现滑动窗口对象检测算法。
假设对每一个滑动窗口都要输入14×14×3的图片,每个滑动窗口最后的输出维度是 1×1×4
假设测试集的单张图片尺寸是 16×16×3,窗口移动步幅为 2, 那我们可以知道一共会有 4 个窗口
所以在下图的第二行最后的输出中,我们可以看到 2×2×4 中的 4个格子,每一个格子都对应一个窗口的 1×1×4 输出
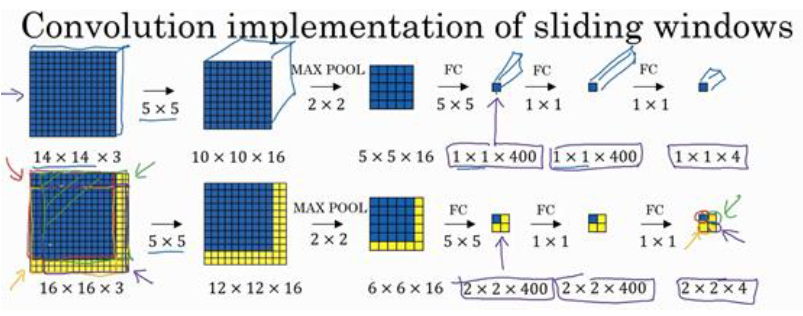
这4次卷积操作中的前几步的神经网络是一样的,所以不用分别为每个窗口去执行前几步的卷积了,大大节省了计算成本
所以该卷积操作的原理是我们不需要把输入图像分割成四个子集,分别执行前向传播,
而是把它们作为一张图片输入给卷积网络进行计算,其中的公共区域可以共享很多计算。
注意:
滑动窗口不能像 图像分类和定位算法 那样输出任意的边框和位置!
每一个滑动窗口的输出只包括 “是否存在”,不包括 “位置和尺寸”! 这也是为什么之前说滑动窗口需要很多的小窗口,所以计算成本大。
每一个窗口的位置和尺寸形状都是预先设定好的!
(四)YOLO算法
(YOU ONLY LOOK ONCE)
滑动窗口卷积算法 仍然存在一个缺点,就是边界框的位置可能不够准确,不能输出最精准的边界框。
因此我们使用 YOLO算法
YOLO 是一种单阶段目标检测算法,相比两阶段方法(如 Faster-RCNN),它速度快,适合实时任务。
单阶段目标检测算法(One-Stage Object Detection):
将目标的位置预测(回归)和目标的分类同时在一个前向过程(single shot)中完成。
类型 特点 代表算法 单阶段(One-Stage) 直接在图像上划分网格并预测框和类别 YOLO 系列、SSD、RetinaNet 双阶段(Two-Stage) 先生成候选框(Region Proposal),再分类/回归 R-CNN、Fast/Mask R-CNN 双阶段:
图像 → 区域提议网络(RPN) → 候选框 → 分类 + 回归 → 目标位置和类别
单阶段:
图像 → 一步完成 分类 + 回归 → 目标位置和类别
YOLO 的流程
- 将图片划分为 S × S 的网格
- 每个网格预测:
- B 个锚框(bounding boxes)
- 每个锚框包含:
- 位置(x, y, w, h)
- 置信度 score(是否含有物体)
- 类别概率(是哪个物体)
输出结构,例如:
S = 7, B = 2, C = 20(VOC 数据集)
输出维度 = 7×7×(2×5 + 20) = 1470
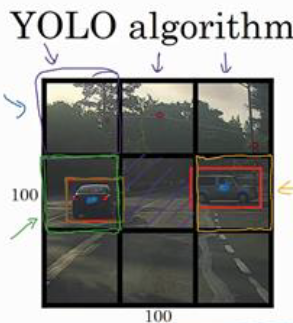
假设输入图像是100×100的,然后在图像上放一个网格。
这里使用用 3×3 网格,实际实现时会用更精细的网格,比如 19×19。
然后使用之前介绍的图像分类和定位算法,将算法逐一应用到 9个格子上
9个格子中的每一个都输出一个8维的标签 𝑦 ,和之前一样��,所以总的输出尺寸是 3×3×8
注意:
- 如果一个目标跨越了多个格子,把它分配给它中心点所在的格子
- 每个方框的左上角是(0,0),右下角是(1,1),
- 是相对于格子尺寸的比例, 需要在0到1之间,可以大于1
YOLO 的优点
- YOLO算法 和 图像分类和定位算法 一样可以输出 具有任意宽高比的边界框 和 更精确的坐标,
而 滑动窗口目标检测算法 的边界框的位置和大小都是预先固定的 - YOLO算法 可以输出多个目标,而 图像分类和定位算法 只能输出一个目标
- YOLO算法 并不需要在 3×3网格上跑 9次算法,而是使用了一个卷积网络进行单次卷积,有很多共享计算步骤,所以这个算法效率很高。
- YOLO算法 由于是卷积实现,速度非常快,可以做到实时识别
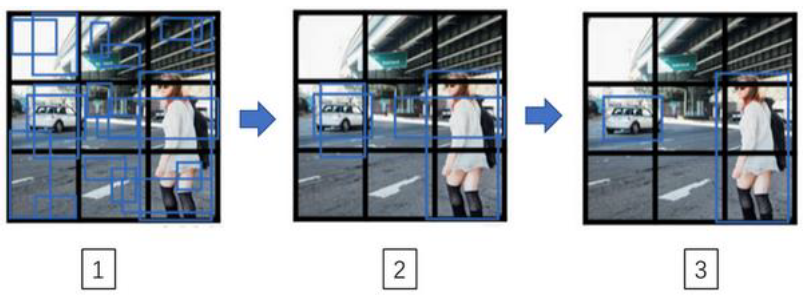
然而现在我们还会遇到一个问题,某个对象会被检测出多次 而不是 一次。
比如下图中不止一个格子会认为这辆车中点应该在格子内部,

这个问题可以用 非极大值抑制 解决,过程如下:
非极大值抑制的流程:
- 看看每个格子输出的概率Pc,删掉所有 Pc < 0.6 的边界框
- 在剩余Pc中选取最大的
- 删除所有 和这个边框有很高交并比的其他边界框 的输出
- 重复 操作2 和 操作3,直到没有框剩下
非极大值抑制意味着你只输出概率最大的分类结果,但抑制很接近但不是最大的其他预测结果,所以这方法叫做非极大值抑制。
注意:
刚刚介绍的是检测单个对象的情况,如果你尝试同时检测三个对象,比如说行人、汽车、摩托,那么输出向量就会有三个额外的分量。 这时候要独立进行三次非极大值抑制,对每个输出类别都做一次
YOLO 架构简述
以YOLOv1 为例
输入图像(448×448×3)
→ 卷积层(提取特征)
→ 全连接层(回归框 + 类别)
→ 输出张量(S×S×(B×5 + C))
YOLOv3 以后采用了 残差网络(Darknet-53)、FPN 多尺度预测,识别精度更强。
(五)锚框
(Anchor Boxes)
到目前为止,对象检测中存在的一个问题是每个格子只能检测出一个对象,
如果想让一个格子检测出多个对象,可以使用 锚框
看下面这个例子
注意行人的中点和汽车的中点几乎在同一个地方,两者都落入到同一个格子中。
正常来说只能从两个结果中选择一个,而锚框可以输出多个

锚框的过程:
-
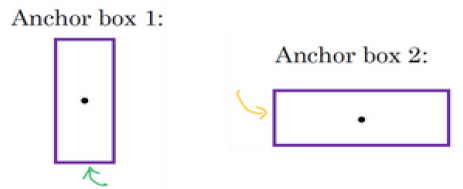
预先定义几个不同形状的 anchor box,一般至少要 5 个, 这里使用 2 个作为示例
-
定义类别标签,不再是
而是 ,
也就是重复了两次,前面的8个参数和第一个框关联,后面的8个参数和第二个锚框关联
由于行人更类似于第一个锚框的形状,车子更类似于第二个锚框的形状,
所以可以用前8个参数来表示行人,后八个参数来表示车子
用anchor box之前,3×3网格的输出 𝑦 是 3×3×8。这里使用了两个锚框,输出 𝑦 是 3×3×(8×2)
注意:
如果你有两个anchor box,但在同一个格子中有三个对象,这种情况算法处理不好,
还有一种情况是,两个对象都分配到一个格子中,而且它们的 anchor box形状也一样,��这也是算法处理不好的
但是这些其实出现不多,所以对性能的影响应该不会很大。
人们一般手工指定 anchor box形状,你可以选择 5到 10个 anchor box形状,覆盖到多种不同的形状·
在锚框于YOLO算法结合时,如果使用 3*3 的格子 和 2 个锚框,那么 9 个格子中任何一个都会有两个预测的边界框,所以要进行非极大值抑制
最后,如果你有三个对象检测类别(行人,汽车和摩托车),那么要对 每个类别 单独运行非极大值抑制
(六)数据集结构
COCO 和 VOC 是目标检测中最常用的 公开数据集格式标准,而不是具体数据集本身。
它们本质上定义的是:“图像 + 标签文件”如何组织和保存,用于训练神经网络识别图像中的物体(目标检测任务)。
| 格式 | 全称 | 特点 |
|---|---|---|
| VOC | Pascal Visual Object Classes | 标签为 .txt,每行:class x_center y_center w h(归一化) |
| COCO | Common Objects in Context | 标签为 .json,结构更复杂,支持分割、关键点等任务 |
1. YOLO 格式数据:
VOC/
├── images/
│ ├── train/
│ └── val/
├── labels/
│ ├── train/
│ └── val/
- 图像是
.jpg - 标签是
.txt,每张图片对应一个同名 txt
每一行是一个目标,格式如下:
class_id x_center y_center width height
注意:
- 所有数值都是 相对于图像宽高的比例,范围 [0, 1]
class_id是类别编号,如 0=猫,1=狗
2. COCO 格式数据:
COCO/
├── images/
│ ├── train/
│ └── val/
└── labels/
├── train.json
└── val.json
- 标签不是单独 txt,而是一个
.json文件 - 所有图像和标签集中在一个 JSON 文件中
- 每个目标使用如下结构描述:
{
"image_id": 42,
"category_id": 3,
"bbox": [x, y, width, height],
"iscrowd": 0
}
bbox 是左上角为起点的矩形框,单位是像素(不是归一化)。
3. VOC 格式数据
- 标注文件为
.xml格式 - 每个图像文件有一个对应的
.xml文件(结构化,嵌套标签) - 所有标注坐标是绝对像素值
- 类别名称是文本(如
"cat"),不是数字
示例结构:
css复制编辑VOC2007/
├── JPEGImages/
│ └── 000001.jpg
├── Annotations/
│ └── 000001.xml
├── ImageSets/
│ └── Main/
│ └── train.txt
每张图片对应一个 .xml 文件,使用 PASCAL VOC 标注规范,常用于早期的深度学习模型。
XML 文件结构如下:
<annotation>
<folder>images</folder>
<filename>0001.jpg</filename>
<object>
<name>cat</name>
<bndbox>
<xmin>112</xmin>
<ymin>95</ymin>
<xmax>312</xmax>
<ymax>390</ymax>
</bndbox>
</object>
</annotation>
- 所有坐标是 像素值(绝对值)
(xmin, ymin)是左上角坐标(xmax, ymax)是右下角坐标
4. 实际示例
假设你有一张图像:dog.jpg,尺寸为 640 × 480,狗的边界框在左上角 (100, 150),宽度为 300,高度为 200,类别编号是 1。
在 YOLO 中:
先归一化:
x_center = (100 + 300 / 2) / 640 = 0.3906y_center = (150 + 200 / 2) / 480 = 0.5208width = 300 / 640 = 0.4688height = 200 / 480 = 0.4167
标签写入 dog.txt:
1 0.3906 0.5208 0.4688 0.4167
在 COCO 中:
你需要在 instances_train2017.json 中写入:
{
"image_id": 1,
"category_id": 1,
"bbox": [100, 150, 300, 200],
"iscrowd": 0
}
4. data.yaml
data.yaml 是一个 数据配置文件,用来告诉 YOLO:
- 你的数据集在哪里?
- 你的数据集有多少个类别?
- 每个类别的名字是什么?
这个文件是 YOLOv5/v8 等 ultralytics 库训练过程中 必须指定的配置项,相当于模型与数据之间的桥梁。
举个完整例子,假设你有 VOC 数据目录结构:
datasets/
└── pets/
├── images/
│ ├── train/
│ └── val/
└── labels/
├── train/
└── val/
你的标签是:
0表示 cat1表示 dog2表示 person
那么对应的 data.yaml 文件内容如下:
path: datasets/pets # 数据集根目录(相对于这个 YAML 文件)
train: images/train # 训练图像路径(相对 path)
val: images/val # 验证图像路径(相对 path)
nc: 3 # 类别数量
names: ['cat', 'dog', 'person'] # 类别名称(顺序要和标签 class_id 保持一致)
注意事项
train和val是图像路径,不是标签路径,YOLO 会自动匹配.txt标签。class_id从 0 开始,必须与names的顺序一致。- 所有路径可以是相对的,也可以是绝对路径(建议相对路径以便迁移)。
当你训练模型时,会传入这个文件名:
model.train(data='data.yaml', epochs=30)
或 CLI:
yolo task=detect mode=train data=data.yaml ...
5. 常用公开数据集
| 名称 | 下载链接 |
|---|---|
| Pascal VOC | http://host.robots.ox.ac.uk/pascal/VOC/ |
| MS COCO | https://cocodataset.org/#download |
| OpenImages | https://storage.googleapis.com/openimages/web/index.html |
| Roboflow | https://universe.roboflow.com/ (超多公开数据集) |
使用 Roboflow(免费的数据集托管 + 转格式平台)
- 登录 roboflow.com,搜索你需要的数据集(例如手势识别)
- 选择导出格式为 YOLOv5 / VOC / COCO
- 下载 ZIP 解压使用
| 需求 | 推荐格式 |
|---|---|
| 使用 YOLO 系列(v3~v8) | VOC(更简单) |
| 使用 Detectron2 / MMDetection | COCO(功能更强) |
| 你想快速上手 | VOC(好处理) |
| 你有复杂标签需求(如实例分割) | COCO |
常见数据集格式转换工具
- Roboflow:可视化转换,支持 VOC、COCO、YOLO 等互转
labelme2coco(JSON)coco-annotator:标注工具,直接输出 COCO 格式- 你也可以自己写脚本完成 VOC↔COCO 的转换
(七)代码实现
下面是一个完整的示例,我们将使用一个开源数据集(包含猫、狗、人),用 YOLOv8 来重新训练,并实现目标检测(分类 + 锚框预测)。
1. 环境准备 & 安装
# 安装 Ultralytics YOLOv8
pip install ultralytics
# 如果用 GPU,确保安装了 PyTorch + CUDA
pip install torch torchvision
根据官方文档,Ultralytics 提供简洁的 CLI(Command Line Interface 命令行接口) 和 Python API,可快速训练自定义数据集 (blog.roboflow.com, colab.research.google.com)。
原生 PyTorch 需要手动搭建网络结构、定义损失函数、写训练循环。这适合科研或教学,但过程繁琐、容易出错,训练效率低。
而 Ultralytics 是一个专门封装了 YOLO 系列模型的 PyTorch 工具包,它的优点包括:
- 快速上手:几行代码即可加载 YOLOv8 并训练
- 自动训练流程:自动处理数据加载、训练流程、评估指标
- 内置模型架构:YOLOv8 的结构和预训练权重都打包好了,无需手写网络结构、损失函数,训练流程极简
- 部署方便:支持导出为 ONNX, TensorRT, CoreML
- 适合快速迭代开发:实时验证、模型版本切换、可视化等
- 支持 COCO/VOC 格式数据集,简单修改
data.yaml
Ultralytics本质上是 基于 PyTorch 封装的高层 API,你用的是 PyTorch,只是不用手动搭模型和训练逻辑了。
2. 数据集准备
Roboflow 上的 Cat & Dog & Human Detection > Browse
数据格式:
- 图片文件:JPEG 格式
- 标注文件:VOC 格式(我们下载为 YOLO 格式)
- 类别:
['dog', 'cat', 'person']
进去后选择 YOLOv8 下载数据集,大概 10 MB, 很快就下好了
项目结构(下载后为), 在当前脚本所在目录的 同级 data 目录下
data
└── cat_dog_person
├── README.dataset.txt
├── README.roboflow.txt
├── data.yaml
├── test
│ ├── images
│ └── labels
├── train
│ ├── images
│ └── labels
└── valid
├── images
└── labels
3. 配置文件 data.yaml
内容如下,已经提供了
train: ../train/images
val: ../valid/images
test: ../test/images
nc: 3
names: ['0', '1', '2']
roboflow:
workspace: cat-object-detect
project: cat-dog-human-detection
version: 1
license: CC BY 4.0
url: https://universe.roboflow.com/cat-object-detect/cat-dog-human-detection/dataset/1
4. 下载模型
我们的项目结构应如下:
.
├── data
│ └── cat_dog_person
├── models
│ └── yolov8
└── 第 11 课:YOLO 算法 demo.ipynb
安装ModelScope
pip install modelscope
下载完整模型库
modelscope download --model AI-ModelScope/YOLOv8 --local_dir /home/heihe/Machine_learning/deep-learning/models/yolov8
5. 完整训练与测试代码
- 导入 YOLOv8
from ultralytics import YOLO
import torch
# 检查设备
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f"使用设备: {device}")
- 训练 YOLOv8 模型
# 训练 YOLOv8s(small)模型,数据集路径指向 data.yaml
model = YOLO('models/yolov8/yolov8s.pt') # 加载预训练模型
results = model.train(
data='data/cat_dog_person/data.yaml', # 数据集配置
epochs=30, # 训练轮数,可根据实际情况调整
imgsz=640, # 输入图片尺寸
device=0 if device == 'cuda' else 'cpu', # 自动选择设备
batch=8, # 批量大小
workers=2, # 数据加载线程数
)
- 验证模型效果
# 在验证集上评估
metrics = model.val()
print(metrics)
- 随机选取一张图片推理与锚框可视化
%matplotlib inline
import random
import glob
import matplotlib.pyplot as plt
# 随机选取一张测试图片
img_list = glob.glob('data/cat_dog_person/test/images/*.jpg')
random_img = random.choice(img_list)
print(f"随机选取的图片: {random_img}")
# 推理
pred = model(random_img)
# 可视化结果
result_img = pred[0].plot() # 绘制检测框
plt.imshow(result_img)
plt.axis('off')
plt.show()

- 批量推理并统计分类命中率
import os
from tqdm import tqdm
test_img_dir = 'data/cat_dog_person/test/images'
test_label_dir = 'data/cat_dog_person/test/labels'
img_paths = glob.glob(os.path.join(test_img_dir, '*.jpg'))
correct = 0
total = 0
for img_path in tqdm(img_paths, desc='批量推理中'):
# 获取图片文件名(不含扩展名)
base = os.path.splitext(os.path.basename(img_path))[0]
label_path = os.path.join(test_label_dir, base + '.txt')
if not os.path.exists(label_path):
continue
# 读取真实标签
with open(label_path, 'r') as f:
gt_lines = f.readlines()
gt_classes = set([int(line.split()[0]) for line in gt_lines])
# 推理
pred = model(img_path, verbose=False)
pred_classes = set([int(x.cls.cpu().numpy()) for x in pred[0].boxes])
# 只要有一个类别命中就算对
if len(gt_classes & pred_classes) > 0:
correct += 1
total += 1
acc = correct / total if total > 0 else 0
print(f"测试集图片分类命中率: {acc:.2%} ({correct}/{total})")
批量推理中: 100%|██████████| 51/51 [00:00<00:00, 77.63it/s]
测试集图片分类命中率: 86.27% (44/51)